
The screenshots you capture and images you generate with Urlbox are valuable. You've of course paid us to render them. But the cost of the work your team have put into researching, developing and/or designing each one may be far higher. They might also include sensitive information that you want to keep privately.
Almost all of our high volume customers now choose to store and distribute their screenshots and images from their own Amazon S3 account. This means they have access to them after our caches would normally expire. They can implement their own deletion policies and have complete control over how they can be accessed.
When you choose to store a screenshot in your own s3 bucket we don't store a copy on our side.
You can connect your own S3 account by adding a set of credentials and designating a bucket via the Urlbox Dashboard:
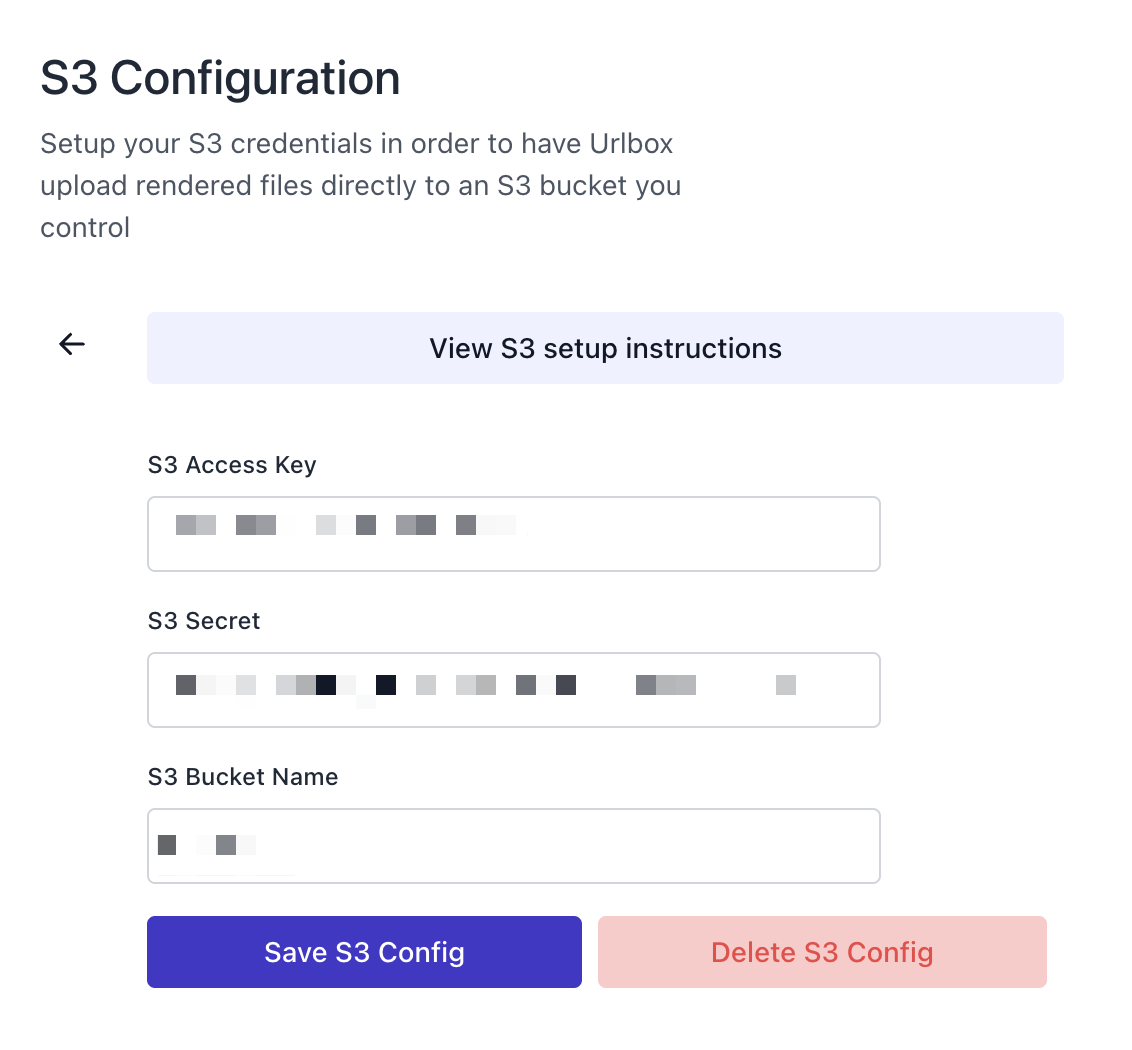
You'll also need to ensure the designated S3 bucket has the right access policies applied. See the full S3 setup instructions linked from that page.
Once correctly configured you can ensure your images are saved to S3 by including the following option in your request:
"use_s3": true
There are three other storage options you've been able to use for a while: s3_path, s3_bucket and s3_storageclass.
But there's now more. You can also save the HTML of the rendered page and json with extracted metadata as well! Here's an example request:
curl -X POST \
https://api.urlbox.com/v1/render/sync \
-H 'Authorization: Bearer YOUR_URLBOX_API_SECRET' \
-H 'Content-Type: application/json' \
-d '{"url":"https://www.bbc.co.uk/news/technology-63635380","use_s3": true, "save_metadata": true, "save_html": true}'You'll get a response back like the following:
{
"renderUrl":"https://mygrabs.s3.amazonaws.com/renders/2022/11/15/2cd22134-fc8d-4ca5-9ac4-8df3769bf340.png",
"htmlUrl":"https://mygrabs.s3.amazonaws.com/renders/2022/11/15/2cd22134-fc8d-4ca5-9ac4-8df3769bf340.html",
"metadataUrl":"https://mygrabs.s3.amazonaws.com/renders/2022/11/15/2cd22134-fc8d-4ca5-9ac4-8df3769bf340.json",
"size": 123,
"renderTime": 6609,
"queueTime": 127,
"bandwidth": 9429299
}You are welcome to take a look at each of those URLs to see exactly what gets saved.
You can also use this with our Webhook feature.