
As a Go developer, the need for programmatically taking screenshots of websites may arise in different scenarios. It may be part of an important feature of an application you're building, such as a website monitor, or even for documentation or compliance purposes. Unfortunately, there are more use cases than there are complete Go-based solutions that adequately tackle this functionality without having to resort to other languages, such as JavaScript. In this article, you will learn about the options you have as a Go developer and some of the flaws they present, as well as how you can fix all that with Urlbox, a fast, accurate, and reliable screenshot API.
You can find all the code used in this article in this GitHub repo.
gowitness
gowitness is an easy-to-use command-line program that is used to take screenshots of web pages. It is built with Golang, and is available on Linux and Mac, with some support for Windows. It uses headless Chrome to navigate web pages and take screenshots. It also captures the metadata of the target sites.
Features
gowitness offers a number of useful features. The following is a non-exhaustive list of features it offers:
- It is a command-line tool with a single, easily installed binary.
- Taking a screenshot of a single URL from the command-line without writing code.
- Specifying dimensions/resolution for a screenshot.
- Running a web service that takes screenshots.
- Batch taking screenshot URLs sourced from a file. This allows you to make a list of URLs, and then have them all captured in a single run.
Using gowitness to Capture Screenshots
In order to start using it, you need to install gowitness directly using the go install command:
$ go install github.com/sensepost/gowitness@latestWith gowitness installed, you can start exploring its functionalities by taking a screenshot of a single URL using the command below:
$ gowitness single https://www.itsfoss.com/install-docker-fedoraThis will create a screenshot with the name of the URL and place it into a screenshot folder in the directory from which the command is executed. The screenshot captured is seen below.
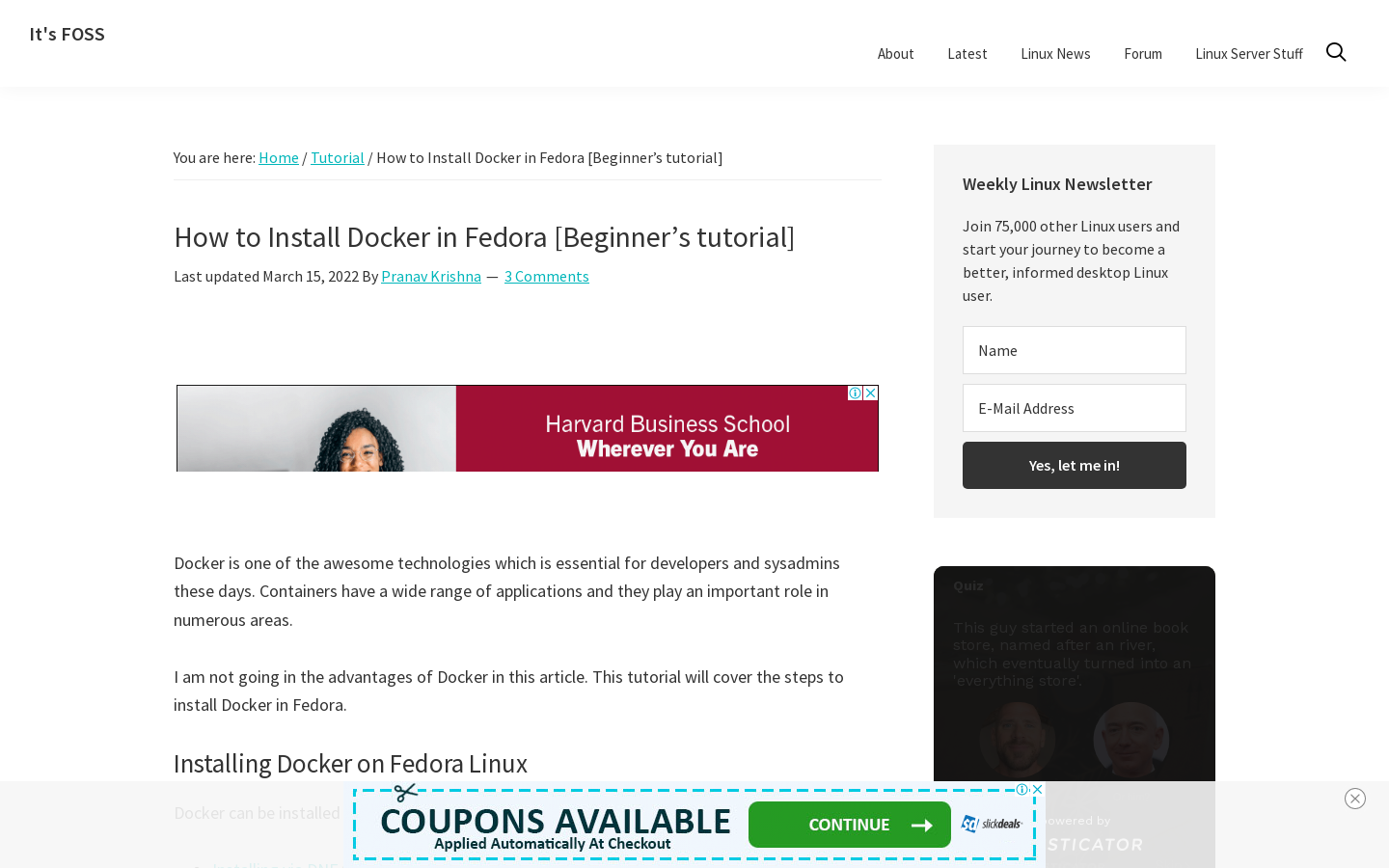
Screenshots taken are 1440 x 900 (width x height) by default, but you can also take a full-page screenshot by including the --fullpage flag with the command, or by including the required dimensions, such as. -X 390 -Y 844, which is good for simulating mobile views. You can take one of each by running the following commands:
# creating a full page screenshot
$ gowitness --fullpage single https://www.itsfoss.com/install-docker-fedora
# creating a mobile view screenshot with width 390 and a height of 844
$ gowitness -X 390 -Y 844 single https://www.itsfoss.com/install-docker-fedora

You can make HTTP calls to grab screenshots directly from your application's codebase by running the executable as a service by using the command gowitness server, as seen below. The screenshot has the same size parameters as before, and can be modified the same way.
$ gowitness --fullpage server
16 May 2022 03:23:40 INF server listening address=localhost:7171This response tells you that the server is running and accessible locally via the URL localhost:7171.
Now create the Go program to capture the screenshots from the gowitness web service. Create a new file, gowitness_api.go, add and save the following code to it:
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"time"
)
func main() {
//calling the function to fetch the screenshot of the URL we want
getImage("www.itsfoss.com/install-docker-fedora")
}
func getImage(site string){
//concatenating the url string to make the request.
screenShotService := fmt.Sprintf("http://localhost:7171?url=%s%s","https://", url.QueryEscape(site))
log.Printf("................making request for screenshot using %s", screenShotService)
//making the get request to the gowitness screenshot service
resp, err := http.Get(screenShotService)
//checking if there are any errors and logging them
if err != nil {
log.Fatalln(err)
}
//We read the response body (the image) on the line below.
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatalln(err)
}
// You have to manually close the body
//but defer closing till the method is done executing and is about to exit
defer resp.Body.Close()
//naming file using provided URL without "/"s and current unix datetime
filename := fmt.Sprintf("%s-%d.png",strings.Replace(site,"/","-",-1), time.Now().UTC().Unix())
// You can now save it to disk...
errs := ioutil.WriteFile(filename, body, 0666)
if errs != nil {
log.Fatalln(errs.Error())
}
log.Printf("..............saved screenshot to file %s", filename)
}The program makes an HTTP request to the gowitness service with the URL you want to capture as a query parameter in the format ?url=domain.com.
This captures a screenshot, which is saved as a PNG image file with the URL captured and the Unix time of capture as its name. As before, it's saved to the directory from which the program was run.
You can run the program by using the go run command in your terminal, as seen below with its output:
$ go run gowitness_api.go
2022/05/16 13:51:11 ................making request for screenshot using http://localhost:7171?url=https://www.itsfoss.com/install-docker-fedora
2022/05/16 13:54:50 ..............saved screenshot to file www.itsfoss.com-install-docker-fedora-1653054890.pngFrom the logs above, you can see that this process took almost four minutes.
This is the screenshot from the program:

Cons of Using Gowitness
While gowitness can seem like an appealing solution, its shortcomings become apparent quickly. Screenshots are sometimes taken before the page has fully loaded, resulting in blank spaces where images are expected to be. In such situations, gowitness provides the command line flag –delay <number_of_seconds> to specify a wait period for the page to load as much as possible before taking the screenshot. Additionally, screenshots of pages with ads include the ads, only some of which have fully loaded, resulting in not just ads, but also odd gaps and places where out-of-position ads are overlapping the content.
gowitness can't be integrated with an existing codebase unless you choose to run it as a service and make HTTP calls to the service to take screenshots, forcing you to run and maintain a service. The web service can take several minutes to finish, and hangs sometimes, dropping the HTTP requests. Additionally, the web service isn't secure, and doesn't allow you to specify the resolution.
chromedp
Built from the ground up in Go with no third-party dependencies, chromedp is a high-level client for the Chrome DevTools Protocol. It enables developers to programmatically interact or automate browser-based actions with web pages and applications. Web scraping, application unit testing, and web page profiling are some of the main use cases for chromedp.
This tool allows you to use code to do almost anything you would do in the browser.
Features
chromedp provides many features. The ones most relevant to this article are as follows:
- Taking a standard screenshot of a web page with the dimensions of your choice.
- Taking a full-page screenshot of a web page.
- Taking a screenshot of a specific element on a web page.
- Exporting a web page to PDF.
- Performing various navigation and interactive activities, such as clicking a button, programmatically.
Using chromedp to Capture Screenshots
chromedp version 0.8.1, the current version as of this writing, works with a minimum of Go version 1.7. You may have to use version 0.8.0 of chromedp if you are running an older version of Go. You can get the package by running the command below:
$ go get -u github.com/chromedp/[email protected]Once you have the chromedp package and dependencies, it's time to take some screenshots with it. First, you'll take a standard screenshot with a specified resolution of 1440 by 900, then you'll take a full-page screenshot of the same page.
To get started with the code, create a new file called chromedp.go, then add the following code and save the file:
package main
import (
"context"
"fmt"
"github.com/chromedp/chromedp"
"io/ioutil"
"log"
"strings"
"time"
)
func main() {
getChromedpScreenShot("www.itsfoss.com/install-docker-fedora",100)
}
func getChromedpScreenShot(site string, quality int) {
//forming url to be captured
screenShotUrl := fmt.Sprintf("https://%s/", site)
//byte slice to hold captured image in bytes
var buf []byte
//setting image file extension to png but
var ext string = "png"
//if image quality is less than 100 file extension is jpeg
if quality < 100 {
ext = "jpeg"
}
log.Printf("................making request for screenshot using %s", screenShotUrl)
//setting options for headless chrome to execute with
var options []chromedp.ExecAllocatorOption
options = append(options, chromedp.WindowSize(1400, 900))
options = append(options, chromedp.DefaultExecAllocatorOptions[:]...)
//setup context with options
actx, acancel := chromedp.NewExecAllocator(context.Background(), options...)
defer acancel()
// create context
ctx, cancel := chromedp.NewContext( actx,
)
defer cancel()
//configuring a set of tasks to be run
tasks:= chromedp.Tasks{
//loads page of the URL
chromedp.Navigate(screenShotUrl),
//waits for 5 secs
chromedp.Sleep(5*time.Second),
//Captures Screenshot with current window size
chromedp.CaptureScreenshot(&buf),
//captures full-page screenshot (uncomment to take fullpage screenshot)
//chromedp.FullScreenshot(&buf,quality),
}
// running the tasks configured earlier and logging any errors
if err := chromedp.Run(ctx, tasks); err != nil {
log.Fatal(err)
}
//naming file using provided URL without "/"s and current unix datetime
filename := fmt.Sprintf("%s-%d-standard.%s",strings.Replace(site,"/","-",-1), time.Now().UTC().Unix(), ext)
//write byte slice data of standard screenshot to file
if err := ioutil.WriteFile(filename, buf, 0644); err != nil {
log.Fatal(err)
}
//log completion and file name to
log.Printf("..............saved screenshot to file %s", filename)
}The code above first sets up various options by which chromedp is going to navigate our URL. For instance we are setting the window size to a width of 1400 and a height of 900. Then a context is created using the options. Next, a set of tasks for chromedp to run are configured:
- Navigate to the target URL.
- Wait five seconds to allow content to load or finish animating.
- Capture a screenshot.
You can now run the code by using the go run command, and it should return output similar to this:
$ go run chromedp.go
2022/05/19 19:17:13 ................making request for screenshot using https://www.itsfoss.com/install-docker-fedora/
2022/05/19 19:17:29 ..............saved screenshot to file www.itsfoss.com/install-docker-fedora-1652987849.png
To capture a full-page screenshot, comment out chromedp.CaptureScreenshot(&buf), and uncomment //chromedp.FullScreenshot(&buf,quality),. Now run the code, and you'll see output similar to this:
$ go run chromedp.go
2022/05/19 19:20:44 ................making request for screenshot using https://www.itsfoss.com/install-docker-fedora/
2022/05/19 19:22:21 ..............saved screenshot to file www.itsfoss.com-install-docker-fedora-1652988141.png
These are the resultant screenshots:
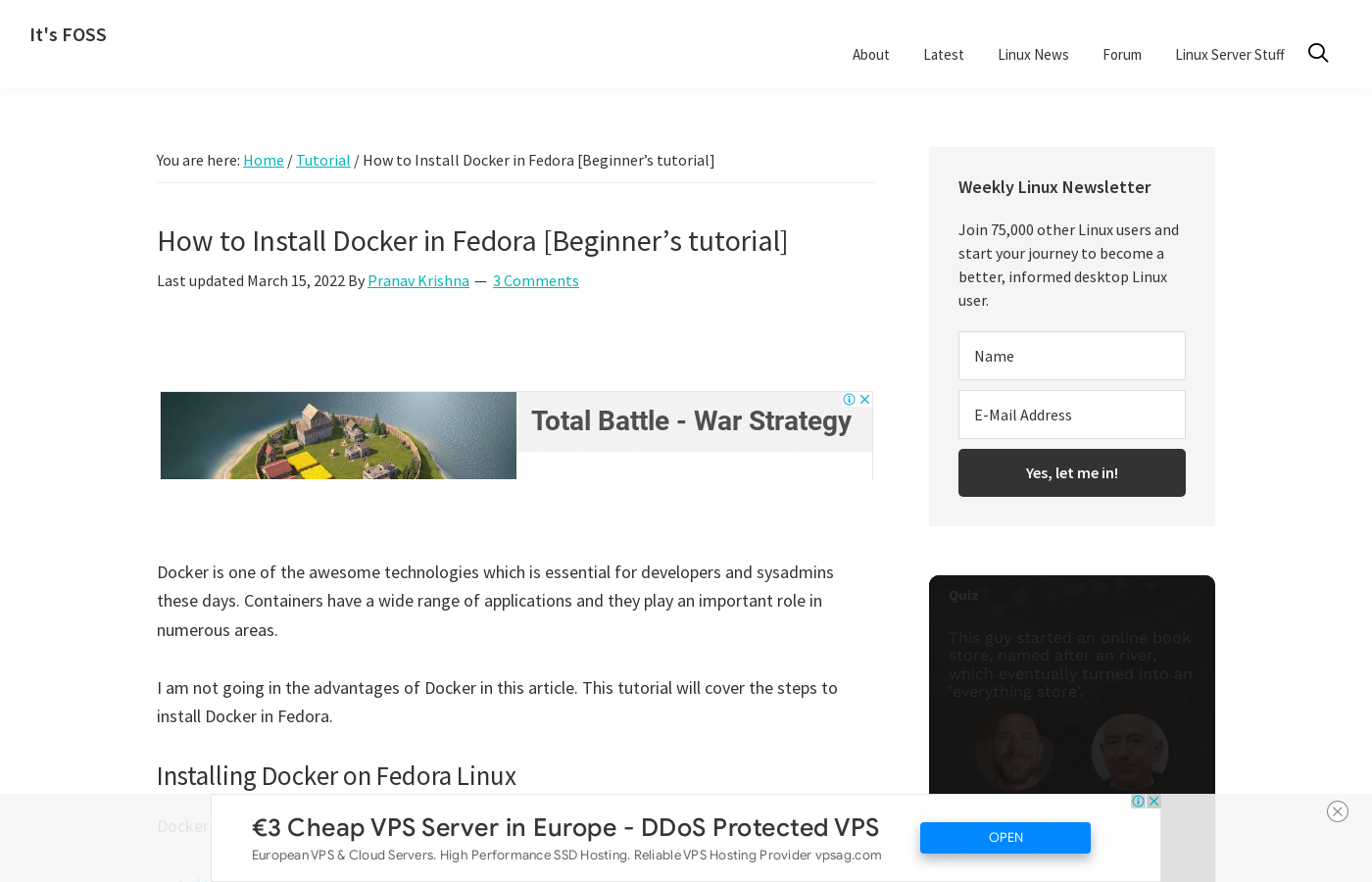

Cons of Using chromedp
The full-page screenshot wasn't taken of a fully loaded page, which is evident from the blank spaces where there should be images. Additionally, since this solution doesn't do anything to minimize or eliminate ads, all the ads that have loaded are captured, as well, and the page ends up with a lot of blank space, and some out-of-position ads running through the content.
You can also see from the output above that the full-page screenshot took a long time to complete, almost two minutes.
Urlbox
Urlbox is a screenshot API service that empowers businesses, developers and users to reliably capture clean screenshots of websites.
Features
Urlbox offers an assortment of unique features, some of which are highlighted below.
- Supports saving or exporting to multiple, including PNG, JPEG, WebP, PDF, and SVG formats.
- You can specify the dimensions or resolution for screenshots, including full-page captures.
- Allows you to block ads, hide cookie banners, and dismiss pop-ups before taking a screenshot. You can even bypass CAPTCHAs.
- Enables you to hide elements using selectors, and prevent other URLs from loading on the page.
- Taking 'retina', or high-definition, screenshots.
- Exporting to PDF has the flexibility of page sizes, and supports setting options for margins, scaling, orientation, background, and many others.
Using Urlbox To Capture Screenshots
Urlbox doesn't offer a Golang package, but they offer a straightforward, well-documented API that can be used to make requests to their APIs using the HTTP client from the Go standard library.
To get started using Urlbox, you'll need to register for a trial account. That provides you with API key and secret, which you'll need to use their APIs. Then, you can create a simple Go program to capture screenshots of websites or web pages.
Create a new file called urlbox.go, and paste in the following code, then save the file:
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
"strings"
"time"
)
func main() {
getUrlBoxImage("www.itsfoss.com/install-docker-fedora", "YOUR-API-KEY")
}
func getUrlBoxImage(site string, apiKey string){
//concatenating the api key and document format to make the request
screenShotService := fmt.Sprintf("https://api.urlbox.com/v1/%s/png?", apiKey)
//creating a map of key-value pairs of Urlbox API options
params := url.Values{
"url": {site},
"width": {"1400"},
"height": {"900"},
}
//Configuring the request with the method, URL, and body
req, err := http.NewRequest("GET", screenShotService, nil)
if err != nil {
log.Fatalln(err)
}
//encode values into URL encoded form/query parameters
req.URL.RawQuery = params.Encode()
//printing out to console the entire request url with params. You can comment this out
fmt.Println(req.URL.String())
//Create a default HTTP client to make the request
client := &http.Client{}
//making the get request to the Urlbox screenshot API
resp, err := client.Do(req)
if err != nil {
log.Fatalln(err)
}
//defer closing of body till the method is done executing and about it exit
defer resp.Body.Close()
//We read the response body (the image) on the line below.
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatalln(err)
}
//naming file using provided URL without "/"s and current unix datetime
filename := fmt.Sprintf("%s-%d.png",strings.Replace(site,"/","-",-1), time.Now().UTC().Unix())
// You can now save it to disk...
errs := ioutil.WriteFile(filename, body, 0666)
if errs != nil {
log.Fatalln(errs.Error())
}
log.Printf("..............saved screenshot to file %s", filename)
}As you can see, the code above is very simple.
- You create a function called
getUrlboxImage. This function accepts two strings as arguments: the target URL, and the API key to authenticate the request. - Next, you initialize map values of the various options to define how the screenshots should look. In this example, only options for height and width are specified. A detailed reference to the options and what they do can be found in the documentation.
- An HTTP GET request with the URL and encoded query parameters is configured and made to the API endpoint. This request is checked for errors, and any errors are logged.
- Finally, the body of the response, which is expected to be a PNG file as specified in the request URL, is read and written to a file using the URL and the current timestamp as the file name. Additionally, a log message is created with the filename.
Run the program:
$ go run urlbox.goThis is the screenshot obtained:
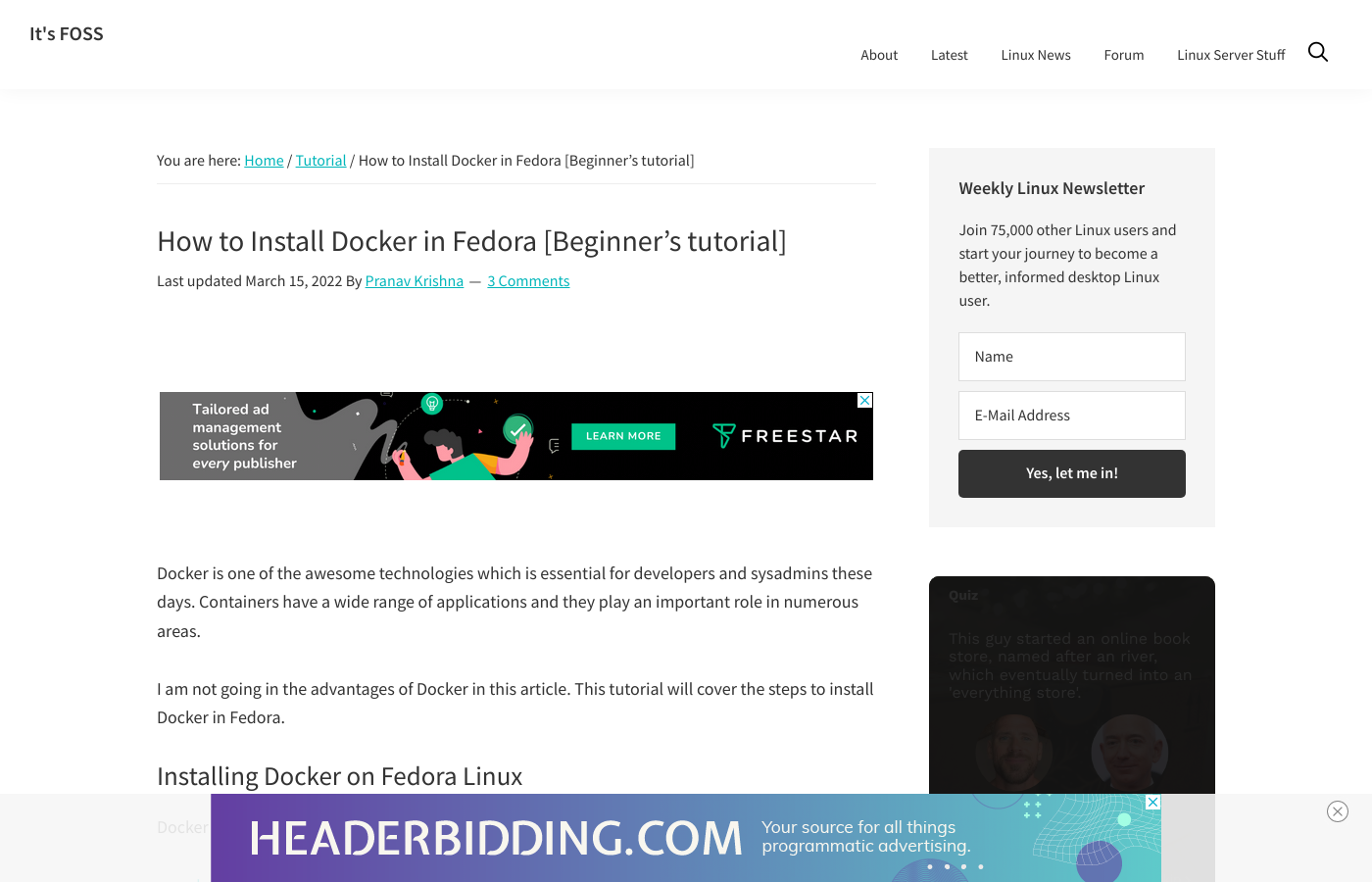
To see what Urlbox brings to the table, you'll take two screenshots: one with the ads, and one in which the ads and other intrusive elements have been blocked.
First, modify the map of options as below to capture a full-page screenshot with ads. Run the program to take your first capture.
//creating a map of key-value pairs of Urlbox API options for full page with ads
params := url.Values{
"url": {site},
"width": {"1440"},
"full_page": {"true"}, ///for full page screenshot
}Now, it's time to apply some of Urlbox's magic to the screenshot. Modify the options as shown and commented in the code block below, and run the program to capture the full page without ads or banners.
//creating a map of key-value pairs of Urlbox API options for full page without adds
params := url.Values{
"url": {site},
"width": {"1400"},
"full_page": {"true"}, //for full page screenshot
"block_ads": {"true"}, //remove ads from page
"hide_cookie_banners": {"true"}, //remove cookie banners if any
"click_accept": {"true"}, //click accept buttons to dismiss pop-ups
}Below are the two images captured. You can see how easy it is to get a great screenshot without any hassle. Unlike the other screenshots you've taken in this tutorial, all images show fully in both versions, and the content is where it should be. It's also significantly faster than the other options.


Conclusion
As a Go developer, you don't have many options to automate website screenshots. As you've seen in this article, common options have some serious drawbacks, including slow response times and cluttered, half-loaded screenshots with out-of-place ads obscuring the content. This article also introduced you to Urlbox, a better way to take screenshots. It produces perfect, ad-free, visually clear screenshots, and it doesn't require that you build and maintain your own screenshot service.