
As a developer, you might have come across a situation where you need to take screenshots of web pages. For example, you might want to take regular screenshots of a website for compliance or monitoring purposes, generate a PDF invoice from an invoice on a web page, or create image assets from dynamic HTML, CSS, and SVG.
When taking screenshots of websites, many solutions include some form of JavaScript. You might think you need to write a Node.js app to capture screenshots you can use in Rust. However, this isn't the case! In this article, you'll learn how to take screenshots in Rust using several Rust crates. You'll also see how you can use a screenshot service like Urlbox to make taking screenshots in Rust easier.
Prerequisites
To follow along with the code samples in this article, you must install Rust and Cargo. The code samples in this article are written to run in Rust 1.62.
You will also need to download Google Chrome as some code samples use Google Chrome in headless mode.
Finally, depending on your development environment, you may need to install a C compiler, which Rust will use to build some dependencies. One such compiler is the GCC compiler.
You can also find all the code in this article in the associated GitHub repository.
Getting Started
You will first create a new Rust project using Cargo. Open a terminal and type the following Cargo command:
cargo new rust-screenshotsThe command will create a new Rust project in the rust-screenshots folder. Then, you can open the folder in your favorite code editor and follow the code samples below.
Using the headless_chrome Crate
The headless_chrome crate is the Rust equivalent of Puppeteer, a JavaScript library that lets you control Chrome or Chromium from a Node.js application. The crate lacks some of the functionality found in Puppeteer, but it does support screenshotting webpages.
To install headless_chrome, open your Cargo.toml file and add the following line in the dependencies section:
headless_chrome = "0.9.0"You can now open the main.rs and add the following code:
use std::fs;
use headless_chrome::{Browser, protocol::page::ScreenshotFormat};
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Open a new instance of Chrome
let browser = Browser::default()?;
// Chrome always opens with one tab open, so
// you just get that initial tab.
let tab = browser.wait_for_initial_tab()?;
// Navigate to the website and wait for it to
// finish loading
tab.navigate_to("https://www.howtogeek.com/")?;
tab.wait_until_navigated()?;
// Screenshot the page to a PNG file and return
// the bytes for that PNG
let png_data = tab.capture_screenshot(
ScreenshotFormat::PNG,
None,
true)?;
// Save the bytes to a screenshot.png file
fs::write("screenshot.png", png_data)?;
Ok(())
}You'll see that you first create a new Chrome browser instance. You'll not pass in any configuration options, so you can use the default method to start it. You'll notice that you don't have to create a tab—when Chrome opens, it always has one tab open so you can get a reference to the initial tab.
Once you have a reference to the tab, you can use it to navigate to the URL you would like to screenshot. You use the.wait_until_navigated() method to wait for most of the page to load before continuing with code execution. You then take a screenshot of the webpage once it's finished loading. The capture_screenshot method returns the raw PNG bytes, which you can save to a file.
You can build and run the code using the following Cargo command:
cargo runWhen the program has finished executing, you should see a screenshot.png file that looks something like this:
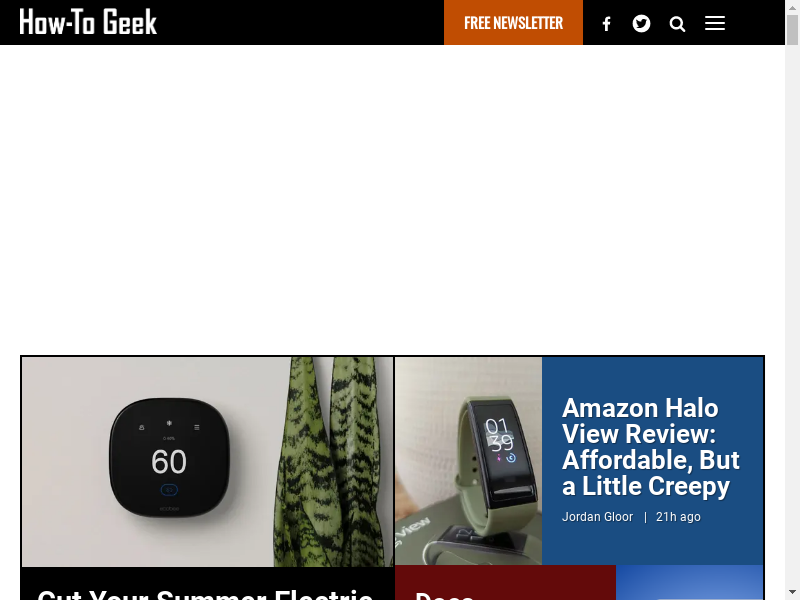
It's not very impressive. The page doesn't look like it finished loading, and the browser's window size is too small. There is also an unappealing sidebar on the right side of the screenshot.
The headless_chrome crate does offer features that might fix some of these issues. You can enter the code sample below into your main.rs file:
use std::fs;
use std::thread::sleep;
use std::time::Duration;
use headless_chrome::{LaunchOptionsBuilder, Browser, protocol::page::ScreenshotFormat};
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Configure the launch options for Chrome before
// starting the browser.
let options = LaunchOptionsBuilder::default()
// Make the window bigger
.window_size(Some((1920, 1080)))
.build()?;
// Open a new instance of Chrome with the specified
// options
let browser = Browser::new(options)?;
let tab = browser.wait_for_initial_tab()?;
tab.navigate_to("https://www.howtogeek.com/")?;
tab.wait_until_navigated()?;
// Sleep for some more seconds to make sure everything
// has loaded
sleep(Duration::from_secs(5));
let png_data = tab.capture_screenshot(
ScreenshotFormat::PNG,
None,
true)?;
fs::write("screenshot.png", png_data)?;
Ok(())
}You'll notice a few differences in the code sample above. First, instead of using the default configuration to start Chrome, you're now going to create a LaunchOptions object using the LaunchOptionsBuilder. This object will let you configure browser settings, such as the window size, allowing you to take a better screenshot. Once you've configured the LaunchOptions object, you can pass it to the Browser constructor. The code also calls the sleep method, which gives the page more time to load in the browser before taking a screenshot. The remaining code is like the first code example.
You can rerun the code and should see the following screenshot:
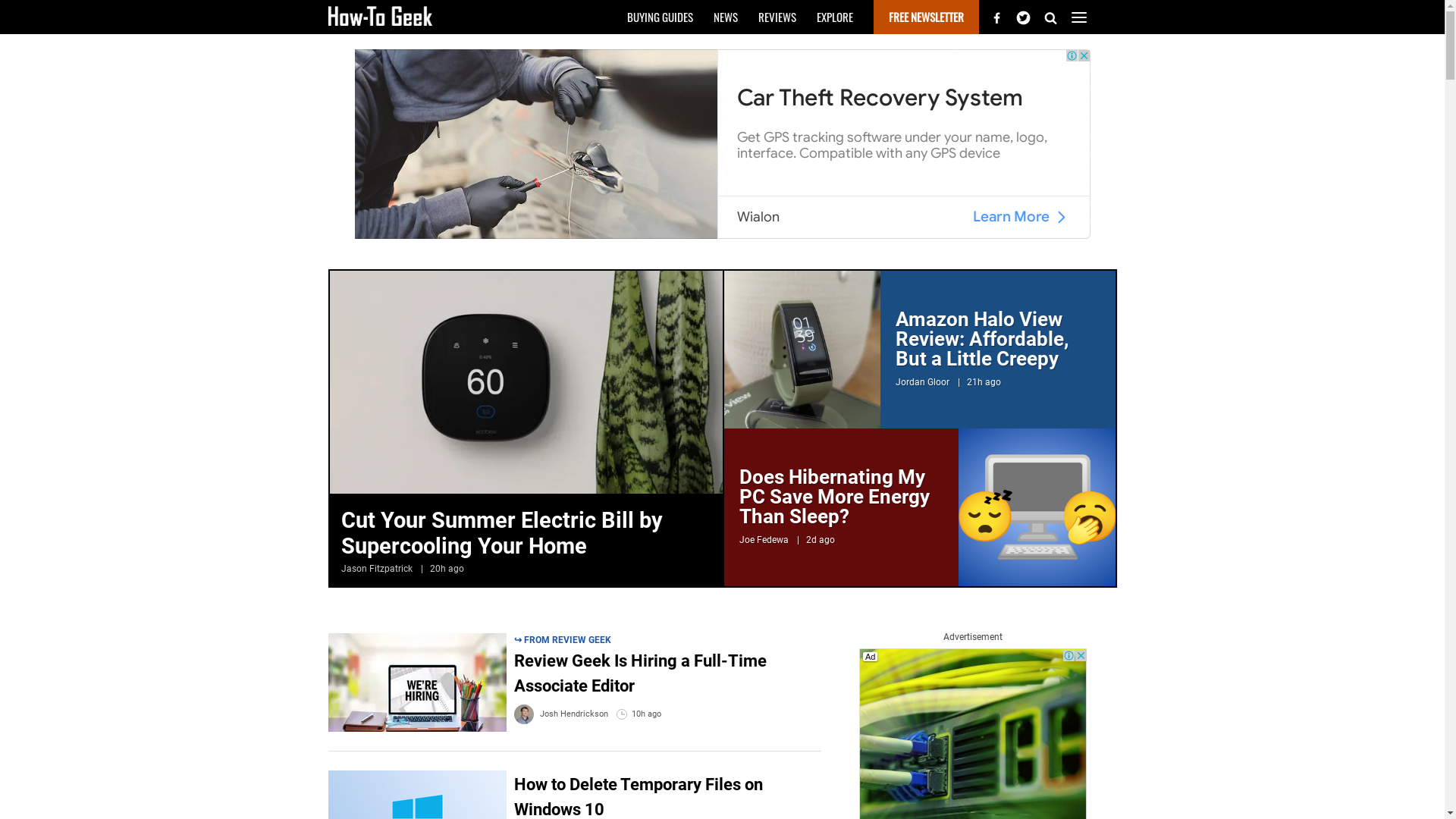
The screenshot looks better than the first attempt. The viewport is bigger, so more of the actual website is visible in the screenshot. The page was also able to load before taking the screenshot. The disadvantage is that ads appear on the web page's top and right. The unappealing scrollbar is also still there, though it's less prominent.
Using the webscreenshot Crate
The webscreenshot crate is another library that lets you take website screenshots. The library aims to minimize the code needed to take a website screenshot. It has a method to screenshot a given URL and another to save that screenshot to a file. The library uses the headless_chrome crate you saw in the previous code sample.
To add the crate, remove all your existing dependencies in your Cargo.toml file and add the following code:
webscreenshot = "0.2.2"You can then replace the code in your main.rs file with the following:
use webscreenshotlib::{screenshot_tab, write_screenshot, OutputFormat};
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Take a screenshot and save the image to a variable
let image_data = screenshot_tab(
// The URL you would like to screenshot
"https://www.howtogeek.com/",
// The output format for the screenshot
OutputFormat::PNG,
// Quality - ignored for PNG
100,
// Whether to screenshot visible only or not
true,
// The width of the browser
1920,
// The height of the browser
1080,
// The element that should be screenshotted.
// We leave it blank to screenshot everything.
"")?;
// Write the screenshot you took earlier to a file
write_screenshot("screenshot.png", image_data)?;
Ok(())
}Run the code using the following Cargo command:
cargo runYou should see a screenshot like the one below:
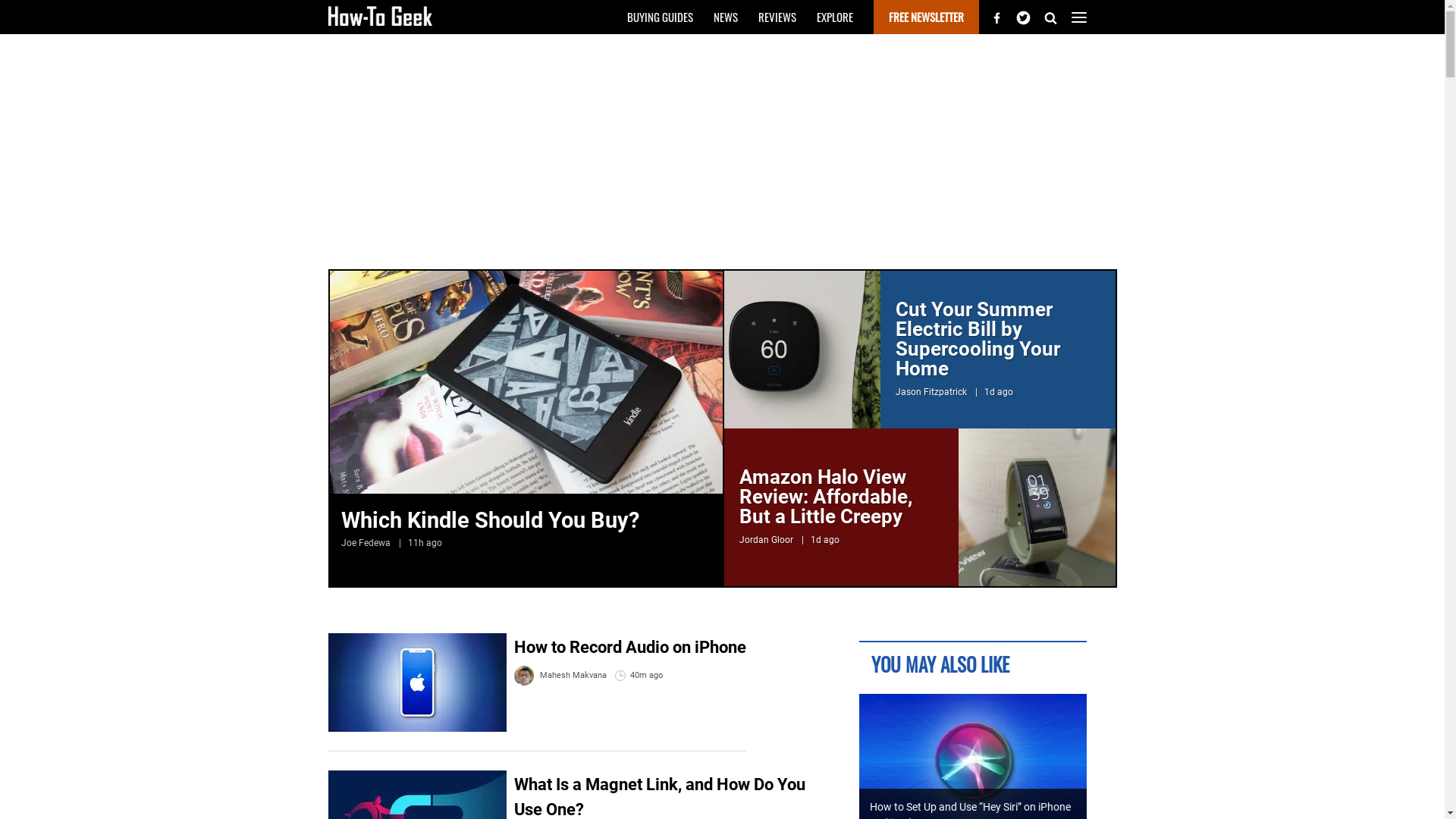
The screenshot looks very similar to the screenshot taken with headless_chrome, but one difference is that there are no advertisements in this screenshot. The missing advertisements aren't due to ad blocking, but rather because the library does not appear to wait long enough for the advertisements to load. If ads had loaded with the page, they would have been included in the screenshot. You can also see that the unappealing scrollbars on the right are still present in the screenshot.
Using the wkhtmltopdf Utility and Crate
wkhtmltopdf is an open source, command-line utility that converts HTML to PDF and several image formats. Libraries exist for several programming languages that let you use wkhtmltopdf from those languages. Rust is one such language. You can use the wkhtmltopdf crate to call the wkhtmltopdf utility from Rust.
Before using this crate, you must install wkhtmltopdf on your computer. The utility is cross-platform, and you can find installation instructions for your particular platform on their download page. Once you've installed the utility and confirmed that it works, you can add the wkhtmltopdf crate to your Cargo.toml file:
wkhtmltopdf = "0.4.0"You can now replace the code in your main.rs file with the code sample below:
use wkhtmltopdf::{ImageApplication, ImageFormat};
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Create a new image application that you will use
let image_app = ImageApplication::new()?;
// Use the image application above to take a PNG screenshot
// of the specified URL
let mut image_out = image_app.builder()
.format(ImageFormat::Png)
.screen_width(1920)
.build_from_url(&"https://www.howtogeek.com/".parse().unwrap())?;
// Save the new screenshot to a file
image_out.save("screenshot.png")?;
Ok(())
}The code sample above is brief and offers little in the way of customization options. First, it creates an instance of ImageApplication, letting you interact with the wkhtmltopdf utility. Then the builder() method is used on the ImageApplication to build a screenshot of the specified URL. Before taking the screenshot, you can configure some options, such as the screen width and format of the screenshot. When configuring the screenshot, you call the .build_from_url() method to screenshot a specific URL. After you've captured the screenshot, you save the output to a file.
You can rerun the code using Cargo:
cargo runYou should see a screenshot.png file in your project folder. If you open it, you should see a screenshot that looks something like the screenshot below:
It's important to note that this image had to be significantly compressed in order to be uploaded—the original file size was twenty-six MB. You can change this behavior, but it will require some additional configuration to get it right. You will also notice that wkhtmltopdf took a full-page screenshot, which may not suit your needs. Unfortunately, the wkhtmltopdf crate does not appear to offer an easy way to change this functionality without diving into the low-level module. In addition, while most of the page renders accurately in the screenshot, you might notice that some parts of the page, especially towards the bottom, didn't finish loading before wkhtmltopdf took the screenshot. In addition to being compressed, this screenshot has been cropped to make viewing it more convenient: it was originally twice as long, and the lower half of the image was nothing but white space. Finally, there are also no ads in the screenshot, but this is due to the page being captured before it was fully loaded, as wkhtmltopdf does not have any ad blocking features.
Using the Urlbox Screenshot API
Urlbox is a screenshot API for generating screenshots from URLs. You can capture screenshots of websites in a variety of formats, such as PNG, JPG, WebP, PDF, and even SVG. Urlbox also has support for Google Fonts and emojis, which ensures that your automated screenshots are accurate representations of how the web page should look. You use your own proxy to avoid having your automation blocked by websites. Urlbox also gives you full control over the quality and dimensions of your screenshots, including partial-page screenshots, and lets you create retina-quality screenshots. You can block ads and hide cookie banners so that nonessential elements don't clutter your screenshot—you can even specify a specific part of the site to capture. And the screenshots taken with Urlbox won't have any unappealing scrollbars!
Urlbox has reasonable pricing options that start at $19/month and offer a seven-day free trial that you can use to test their service. They also offer an intuitive dashboard that you can use to test different screenshot options. All the dashboard options are available through a REST API, which you can effortlessly consume in Rust.
Before using Urlbox, you must sign up and retrieve an API key to use in Rust. You will see an API Key and API secret on the dashboard page as soon as you log in. The code sample below will only be using the API key, but it is recommended that you also use the API secret once you become familiar with the Urlbox API and its features.
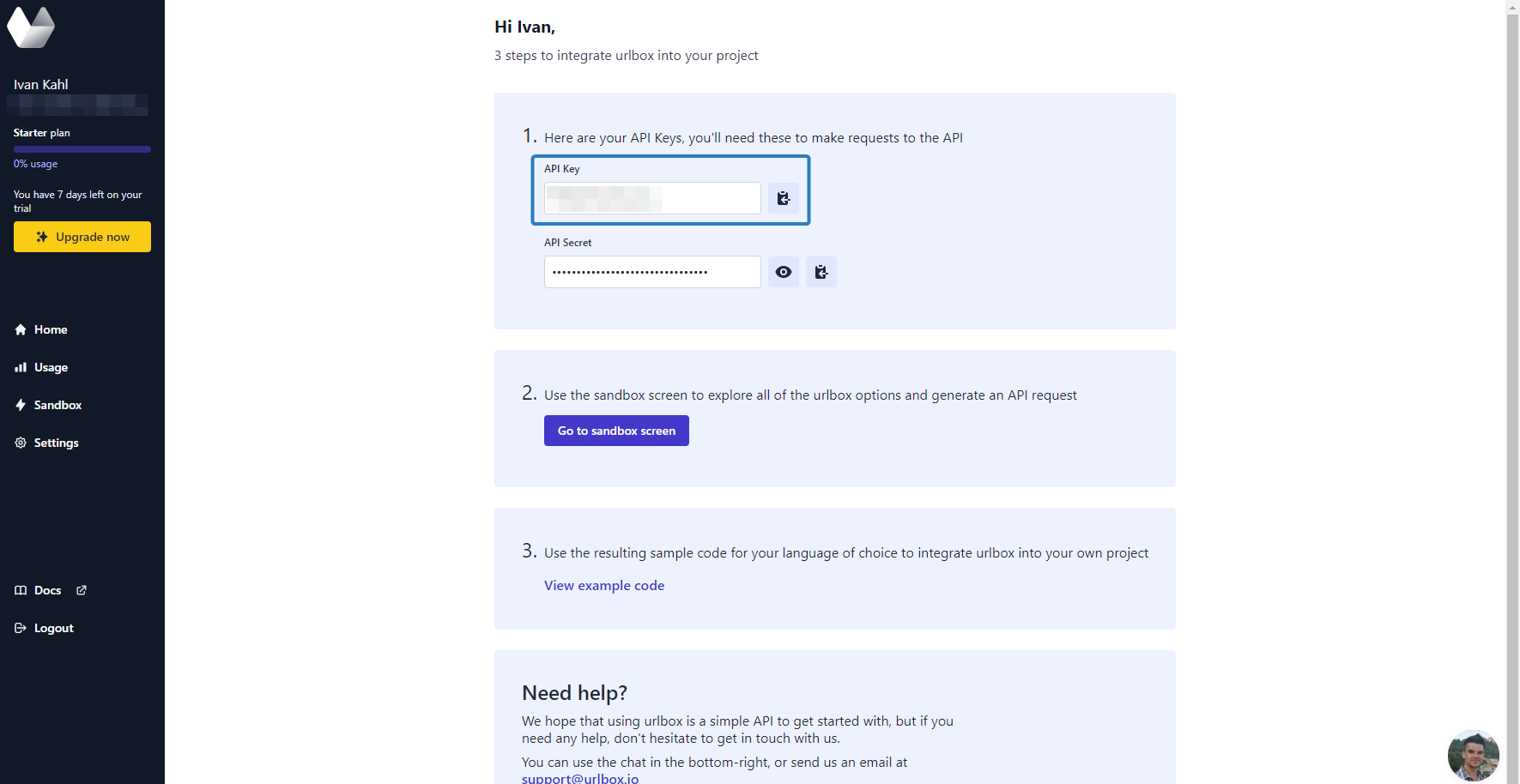
Once you have your API Key, you can add it to your Rust project as an environment variable. You can do this by creating a file called .cargo/config.toml in your project directory and pasting the following content into the file:
[env]
URLBOX_API_KEY = <YOUR_API_KEY>Since you will be using the REST API provided by Urlbox, you will need to add an HTTP client library to your Rust project. The code sample below uses the popular reqwest HTTP client crate as well as the tokio crate to help with asynchronous operations. You will also need to add the futures-util crate so that you can save the screenshot to a file.
Replace the dependencies in your Cargo.toml file with the following:
reqwest = { version = "0.11.11", features = ["stream"] }
tokio = { version = "1.19.2", features = ["full"] }
futures-util = "0.3.21"You can now replace the code in your main.rs file with the following:
use futures_util::StreamExt;
use tokio::{fs::File, io::AsyncWriteExt};
use reqwest::Client;
#[tokio::main()]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Create a new reqwest client which you will use for our REST
// calls to the Urlbox API
let client = Client::new();
// Retrieve your API Key from the environment variables
let api_key = env!("URLBOX_API_KEY");
// Format your REST API URL with the API Key
let api_url = format!("https://api.urlbox.com/v1/{api_key}/png");
// Use the reqwest client to call the REST API URL above
// and return the response as a byte stream which you can
// save to a file.
let mut stream = client.get(api_url)
.query(&[
// The URL you want to screenshot
("url", "https://www.howtogeek.com/"),
// Specify the screen width to use
("width", "1920"),
// Screenshot the entire page
("full_page", "true"),
// Click accept on any popups
("click_accept", "true"),
// Block any ads that might appear on the page
("block_ads", "true"),
// Hide any cookie banners that might appear
("hide_cookie_banners", "true"),
// Screenshot the webpage in retina quality
("retina", "true"),
// Hide a notification dialog that appears
("hide_selector", "#notificationAllowPrompt")
])
.send()
.await?
.bytes_stream();
// Create a new file that you can write the response bytes to
let mut file = File::create("screenshot.png").await?;
// Write the bytes for the screenshot image to a file
while let Some(item) = stream.next().await {
file.write_all_buf(&mut item?).await?;
}
Ok(())
}In the code above, you first create a new instance of the request Client object. Next, you'll use this client to call the Urlbox REST API. Once you have your client, you can construct your REST API call. First, you retrieve the Urlbox API Key stored in your environment variables using the env!() macro, then create a REST API call to the URL using the API Key and format!() macro. The actual HTTP request is then made using .get().
You can see how you can [pass query parameters to configure Urlbox's features. In this example, you're blocking ads, taking a retina quality screenshot, and hiding some elements on the page before taking a screenshot. Once you've received a response, you must convert it to a byte stream which you can then write to the screenshot.png file.
You can run the code sample using Cargo:
cargo runYou should see a screenshot.png file created. When you open it, it should look like this:
The screenshot is retina quality, yet the file size is significantly smaller than when generating a full-page screenshot using wkhtmltopdf. Also, unlike wkhtmltopdf, Urlbox renders the page perfectly from header to footer. In addition, Urlbox's support for modern CSS has ensured that the page layout in the screenshot is the same as if you were to navigate the website yourself. Finally, you'll also notice that there are no advertisements on the web page, but they haven't left gaps of space, either.
You have a beautiful, automated screenshot of a web page that you can now use.
Conclusion
There are many reasons why you might need to take screenshots of web pages programmatically. In this article, you've seen different website screenshot solutions you can use in Rust.
If you want to take screenshots of websites manually, you can make use of the headless_chrome crate, webscreenshot crate, or wkhtmltopdf utility and crate. While these solutions generate adequate screenshots, there are many edge cases such as advertisements and cookie banners that you must consider. You'll be able to set up your screenshot service relatively quickly, but spend significantly more time trying to perfect and maintain it.
If you want to quickly generate screenshots or PDFs of websites with minimal maintenance or overhead, Urlbox is an excellent solution. Its REST API makes it easy to integrate Urlbox into your Rust application. It's also easy to block ads, hide certain elements, and take retina-quality screenshots. You also have the choice to take a screenshot of the viewport, full page, or even a specific element on a web page when using Urlbox.
With Urlbox you can:
Discover the power of the Urlbox in our API docs.
Save yourself some trouble and use Urlbox today to automate your screenshot needs.