
When I started Urlbox in 2012 I did not expect to still be finding fascinating new rendering edge cases in 2024.
This post is the story of how we debugged the following screenshot API issue raised by a customer last week (shared with permission):
Occasionally there are eComm stores where it seems like no matter how much delay & wait_until=requestsfinished, the images never seem to load. With full page, it seems some sites have wacky loading.
With that said, this is rare. I'll include a few examples (where I put a 10 second wait to ensure):
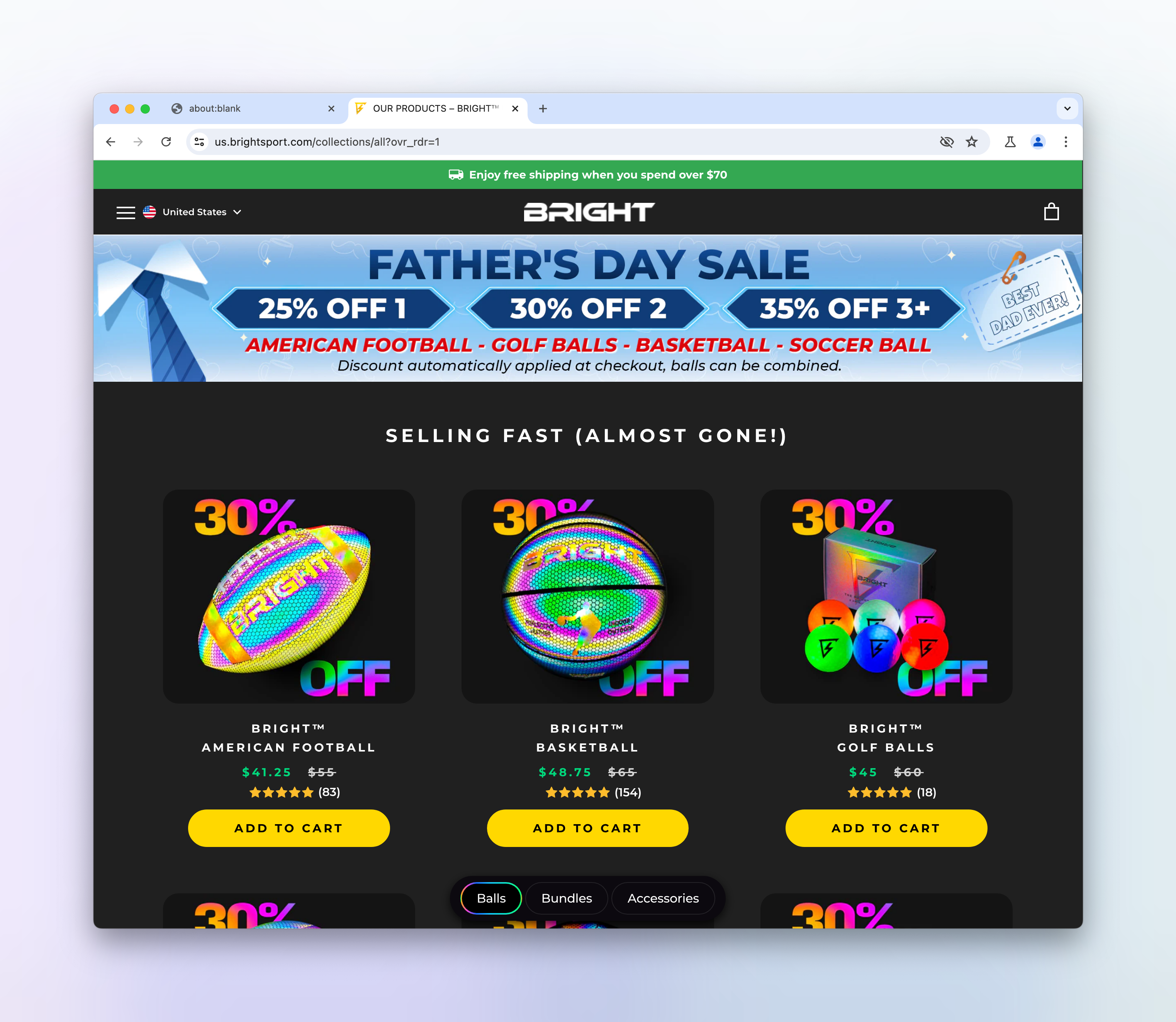
The issue is that images are not loading on some e-commerce websites, making their Urlbox screenshots look like this:

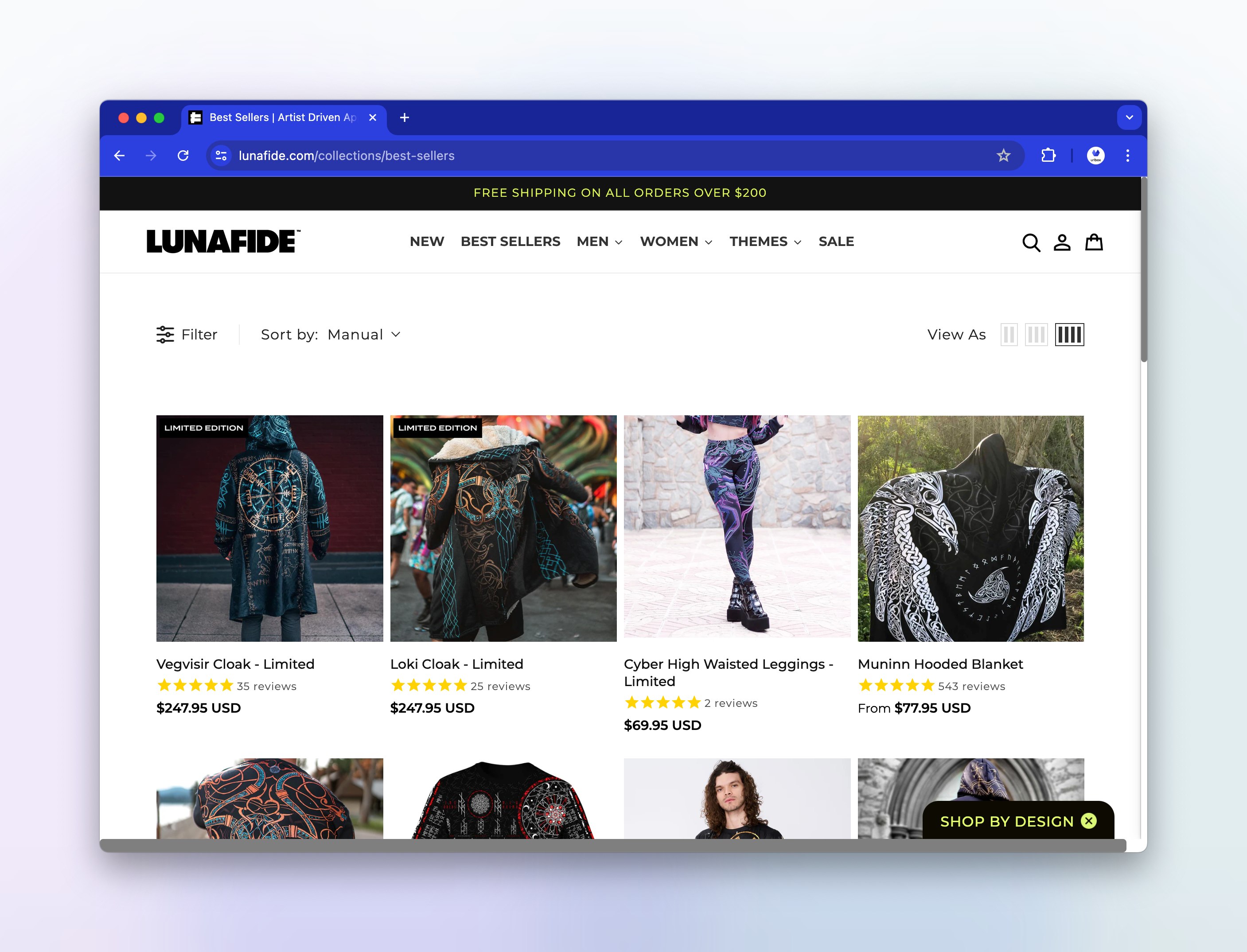
But when viewed in a regular browser, they look like this:
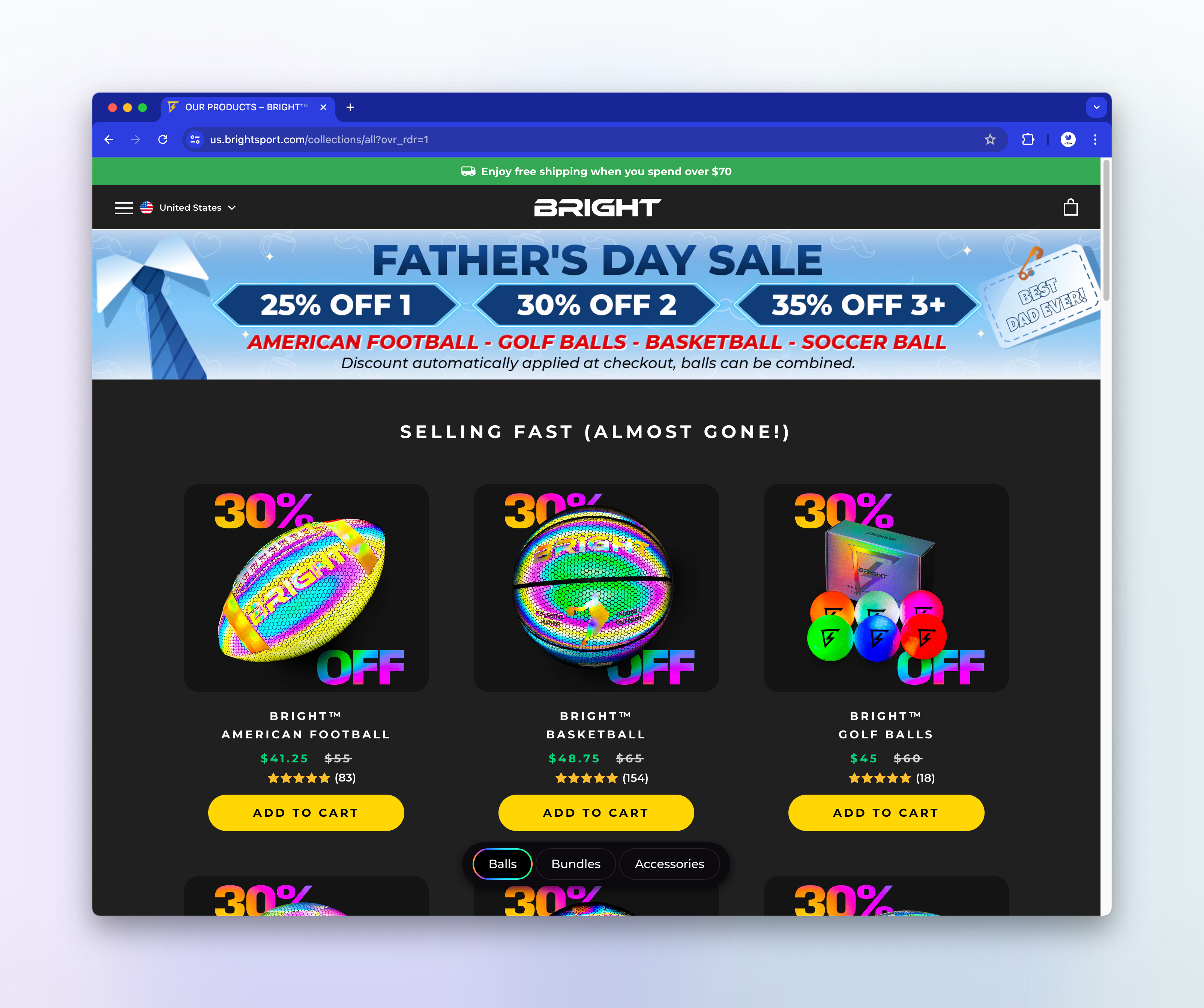
The second link shows a similar issue, with a loading spinner in the screenshot:
But in a regular browser, things are loading correctly:
First step: Confirm the issue
When we receive an issue such as this one we always want to know which other render options the user is passing so that we can see if any of them might be causing the issue inadvertently. It also allows us to try and re-create the issue and confirm it on our end.
The customer reported the issue with some example render links. Render links are URLs that can be used to directly request a screenshot from Urlbox by passing the target url and any render options in the query string. The render links that the customer had crafted looked like this:
https://api.urlbox.com/v1/*****/png?delay=10000&wait_until=requestsfinished&full_page=true&hide_cookie_banners=true&click_accept=true&url=https://us.brightsport.com/collections/all
Lets make those options more readable by converting them into JSON format and explain what each one does:
{
"url": "https://us.brightsport.com/collections/all",
"format": "png",
"delay": "10000",
"wait_until": "requestsfinished",
"full_page": "true",
"hide_cookie_banners": "true",
"click_accept": "true"
}- url - This is the url of the site that the user wants to take a screenshot of.
- format - The user is requesting a
pngscreenshot of the site. - delay - Tells Urlbox to wait 10 seconds (10,000ms) before taking a screenshot.
- wait_until - Waits until all network requests are complete before taking a screenshot.
- full_page - The user wants to receive a full page screenshot, i.e. the entire height of the website.
- hide_cookie_banners - This instructs Urlbox to try to remove any cookie banners and other potential modals from the site before taking a screenshot. This is done by using CSS and JS to set the elements to
display:none !important;. - click_accept - This option tells Urlbox to find buttons within cookie banner dialogs labelled "Accept" or similar, and send a click event to them, in an attempt to 'accept' storing cookies, thereby removing the banner from the screenshot.
It is quite surprising that the images on this particular website are failing to load given that the user requested a 10 second delay, plus they also added in the wait_until=requestsfinished option.
We'll try to run the request without any additional options to see if the issue still occurs. We can use our own developer sandbox to quickly load and run the screenshot request without any render options:
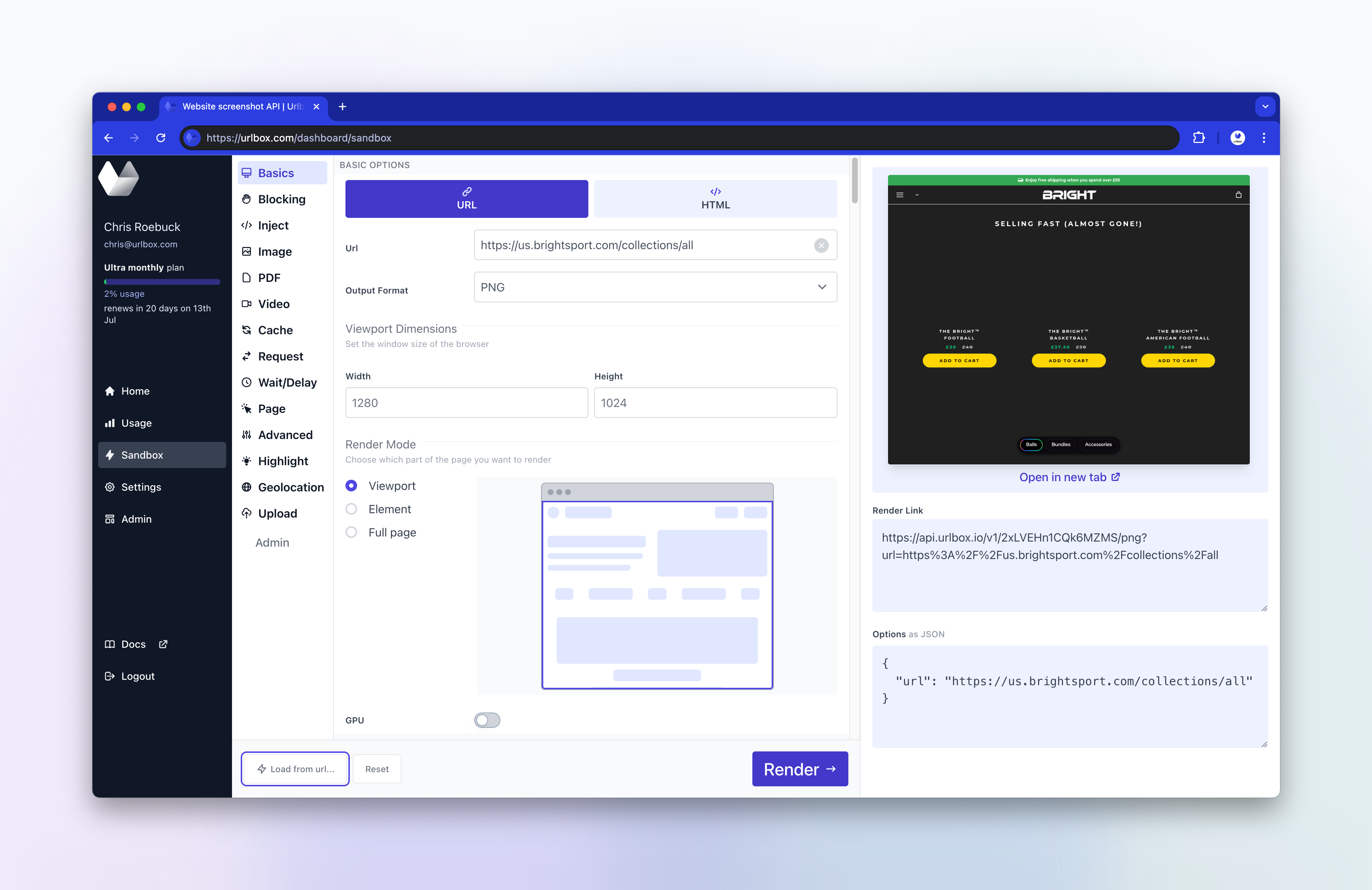
We can see the issue still occurs without any additional render options. Looking at our browser logs, I can see there are no obvious javascript errors coming from the browser.
Time to try and re-create the issue locally...
Second step: Try to re-create the issue locally
When running the same screenshot request in my local development environment, the issue does not occur and the images are loading correctly.
The main differences between my local environment and production are:
- Geography - my location and IP address will be detected as being in the UK, whereas our servers are US based primarily.
- Platform - my local machine is a macbook pro, whereas our headless browsers run in ubuntu-based containers. Additionally, my macbook has a GPU, however our regular headless browsers do not, although by default we run with the
--disable-gpuchrome flag so gpu is disabled in both. (It is possible to run a Urlbox request on a browser with a gpu enabled, by setting thegpuoption to true, exclusive to users on our Ultra plan.)
Number 1 is easy enough to simulate, by connecting to a VPN with an IP address based in the US. For this I use Proton VPN. It would be unusual if a site was choosing to block images to US-based visitors, but let's test anyway.
When running the request locally and connected to the VPN, the issue does not occur, so it is looking like a platform specific difference causing the issue.
Number 2 is harder to simulate, but I'm aware that sites will sometimes do user-agent sniffing and serve different content based on the user-agent. Using urlbox, I can simulate this by setting the user_agent option to set the user-agent in the Urlbox headless browser to match the user-agent of a regular chrome browser:
https://api.urlbox.com/v1/****/png?url=https%3A%2F%2Fus.brightsport.com%2Fcollections%2Fall&user_agent=Mozilla%2F5.0%20%28Windows%20NT%2010.0%3B%20Win64%3B%20x64%3B%20rv%3A89.0%29%20Gecko%2F20100101%20Firefox%2F89.0
When running the request with the user-agent set to a regular chrome browser, the issue still occurs, so it doesn't appear to be user-agent sniffing that is causing the issue.
Going Deeper: Inspecting the source
Intrigued to find out what is preventing these pesky images from showing, I crack open the devtools in a regular chrome browser and take a look at the html of the images.
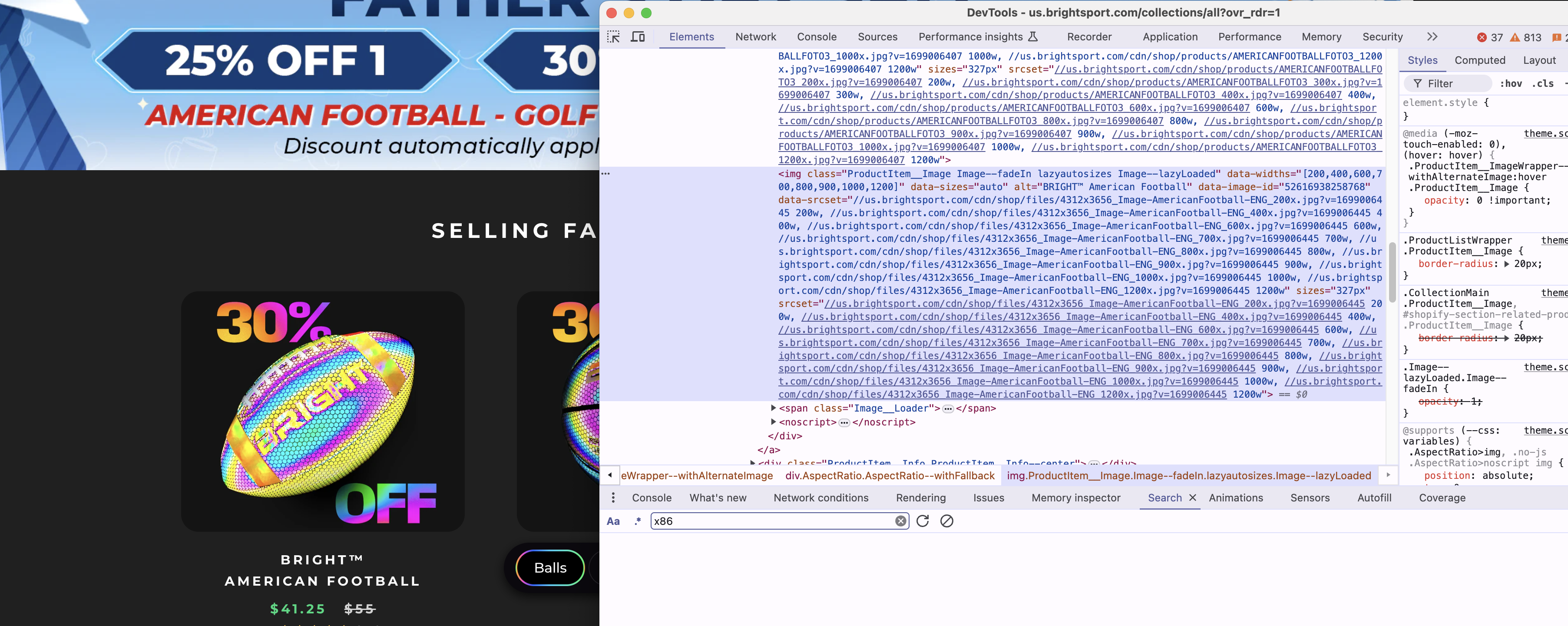
It looks like the images are using the srcset attribute but without any src attribute, (which is a bit surprising as I had thought that the src attribute was still required for them to work, but it appears not). Could this possibly be why the images fail to load for us? I don't think so, and a quick google for puppeteer img srcset doesn't throw up anything obvious.
It's also interesting seeing the classnames lazyautosizes and Image--lazyLoaded along with the data-srcset attribute, this suggests that some kind of plugin is controlling the loading of these images.
There's also a <noscript> tag accompanying each <img>, presumably this is used as an image fallback for any visitors that have disabled javascript in their browsers.
We can simulate running a browser with javascript disabled in Urlbox by passing the disable_js option. When running with this option, the images do appear in the screenshot.
However, the issue with disabling javascript is that it also disables most useful Urlbox features. For example, the customer in this case wanted a full page screenshot of the site. With javascript disabled, it isn't possible to take a full page screenshot, as we need to run javascript in order to determine the full height of the page.
Let's try and inspect the html from urlbox's headless browser and see if there is anything obvious. Since Urlbox also allows you to return the fully loaded html of the page, we can simply run the screenshot request again but with format option set to html. Again we'll use our sandbox for this:
We can also use the download option so that when opening our html, it will automatically download to our machine, using the filename specified in the download option. This just sets the content-disposition header which instructs your browser to download the file rather than open it in a tab:
https://api.urlbox.com/v1/****/html?url=https%3A%2F%2Fus.brightsport.com%2Fcollections%2Fall&download=remote.html
Opening the downloaded remote.html file, the first thing that strikes me is there are a lot of scripts - the <head> portion of the html is 414 lines long! The entire html file is 3676 lines long, so it seems like quite a hefty page with lots of third party assets such as scripts, stylesheets, iframes being loaded. There are also a lot of inline scripts in both the <head> and the <body>. It's clear from some of the asset URLs that this is a shopify store.
Scrolling down to the <img> within the <div class="ProductItem">, it's obvious that in the working screenshot's html, the img tags have been enriched, presumably by some javascript inside a plugin, whereas in the remote screenshot html, the img tags don't appear to have been altered. You can see the diff between the two htmls below:

Further, the working images have the class Image--lazyLoaded whereas the blank images have the class Image--lazyLoad. Doing a find all search for these classes in devtools brings me to this piece of embedded javascript in the <head>:
<script>
// This allows to expose several variables to the global scope, to be used in scripts
...
window.lazySizesConfig = {
loadHidden: false,
hFac: 0.5,
expFactor: 2,
ricTimeout: 150,
lazyClass: 'Image--lazyLoad',
loadingClass: 'Image--lazyLoading',
loadedClass: 'Image--lazyLoaded'
};
...
</script>From a quick google, it looks like the site is using this aFarkas/lazysizes script to lazy load the images, and I can see where it is imported in the <head>:
<script
async=""
data-src="https://us.brightsport.com/cdn/shop/t/61/assets/lazysizes.min.js?v=174358363404432586981716100765"
type="text/lazyload"
></script>The github mentions that the lazysizes plugin includes a JS API that will add the lazySizes object to the window. In my local browser, I can see that the window.lazySizes is available.

Now I would like to know what happens when I run window.lazySizes.init() in the console. Luckily, Urlbox allows us to run javascript in the context of the running page by passing the js option, so I can give it a try:
https://api.urlbox.com/v1/****/png?url=https%3A%2F%2Fus.brightsport.com%2Fcollections%2Fall&js=window.lazySizes.init()
Alas, no dice, the images are still not showing up. In order to really get to the bottom of what is going on I need to debug interactively in the remote headless browser...
Debugging in production with devspace
At urlbox, we host our headless browsers in containers within managed kubernetes clusters.
Being able to debug in an environment as close to production as possible is sometimes essential in order to re-create and figure out what might be causing differences between our local environment and our production setup.
We're going to use a handy tool called Devspace created by loft.sh to debug in a production-like environment.
Devspace allows us to use the exact same container image as we use in production, but override some of its configuration to make it act like a development environment.
For example, we can override the entrypoint or the command of the container to run a different command.
Once configured, Devspace also syncs our local src files with the container, so we can make changes to the code and see the effects in real-time.
Additionally, Devspace allows us to forward ports from the container to our local machine, so we can set breakpoints and debug within our nodejs process running in the container.
Here's a sample of our devspace.yaml file:
version: v2beta1
name: urlbox
pipelines:
dev:
run: |-
start_dev renderer
dev:
renderer:
env:
- name: LOG_LEVEL
value: "debug"
labelSelector:
app: renderer-debug
workingDir: /home/urlbox/apps/renderer
command: ["./entrypoint-debug.sh"]
sync:
- path: ./apps/renderer/config/entrypoint-debug.sh:/home/urlbox/apps/renderer/entrypoint-debug.sh
disableDownload: true
startContainer: true
onUpload:
exec:
- command: |-
chmod +x entrypoint-debug.sh
restartContainer: true
- path: ./apps/renderer/src:/home/urlbox/apps/renderer/src
disableDownload: true
excludePaths:
- node_modules
- path: ./apps/renderer/package.json:/home/urlbox/apps/renderer/package.json
disableDownload: true
onUpload:
exec:
- command: |-
cd ../../ && yarn install --production=false
restartContainer: true
ports:
- port: "6000"
- port: "9229"This sets up a pipeline called dev which looks for a pod running in our cluster with a label of app equal to renderer-debug.
Once it finds such a pod, it will create a new devspace controlled pod using the exact same image as our pod, but overrides the command to run ./entrypoint-debug.sh.
In the sync section, we sync the entrypoint-debug.sh script and make it executable onUpload. This entrypoint-debug script installs some developer tools like nodemon and ts-node which allows us to restart the nodejs process whenever a typescript src file is changed.
We change the way our node app is run - instead of node dist/server.js we change it to nodemon --inspect src/server.ts and nodemon will use ts-node to transpile our changed typescript files on the fly. The --inspect command line flag lets us attach a remote debugger for our node app on port 9229.
We also tell devspace to sync our local ./apps/renderer/src directory with the /home/urlbox/apps/renderer/src directory inside the container. We add environment variables inside the container using the env section, for example here setting the LOG_LEVEL to debug. Finally, we forward the container's 6000 and 9229 ports to our local machine.
To start devspace, we call devspace dev in the terminal. This will run the dev pipeline, and once ready we can start making requests to our remote container using http://localhost:6000.
$> devspace dev
info Using namespace 'default'
info Using kube context 'cluster-1'
dev:renderer Waiting for pod to become ready...
dev:renderer Selected pod renderer-debug-devspace-774659cbb8-lm9qz
dev:renderer ports Port forwarding started on: 6000 -> 6000, 9229 -> 9229
dev:renderer sync Sync started on: ./apps/renderer/config/entrypoint-debug.sh <-> /home/urlbox/apps/renderer/entrypoint-debug.sh
dev:renderer sync Waiting for initial sync to complete
dev:renderer sync Sync started on: ./apps/renderer/package.json <-> /home/urlbox/apps/renderer/package.json
dev:renderer sync Waiting for initial sync to complete
dev:renderer sync Sync started on: ./apps/renderer/src <-> /home/urlbox/apps/renderer/src
dev:renderer sync Waiting for initial sync to complete
dev:renderer sync Initial sync completedWe can attach the chrome devtools to the remote nodejs process by navigating to chrome://inspect in a local chromium based browser and clicking Inspect when our remote nodejs target shows up. Now we're able to set breakpoints in the nodejs process from within chrome devtools. You could also attach debuggers from your IDE if you prefer.
To be able to attach to the chromium browsers debugger, we'll first need to modify the part of our code that launches the browser to expose the remote debugging port. We can do this by adding the --remote-debugging-port=9222 and --remote-debugging-address=0.0.0.0 chromium flags to the puppeteer.launch options.
await puppeteer.launch({
headless: true,
args: [
... other chrome flags...
'--remote-debugging-port=9222',
'--remote-debugging-address=0.0.0.0',
]
})When we save this change, devspace will automatically sync the file with the code in our container, then nodemon will notice that a file has changed and restart our node process.
Now when we make a request to the container, Puppeteer will launch the browser with the additional debugging flags.
We port-forward the remote debugging port, 9222 in our case, to our local machine, so that we can attach a debugger to the remote browser's devtools:
kubectl port-forward renderer-debug-devspace-774659cbb8-lm9qz 9222:9222And we tail the logs of the container to see the output:
kubectl logs -f renderer-debug-devspace-774659cbb8-lm9qzIn chrome://inspect, we can see the remote browser target and click inspect to open the devtools:
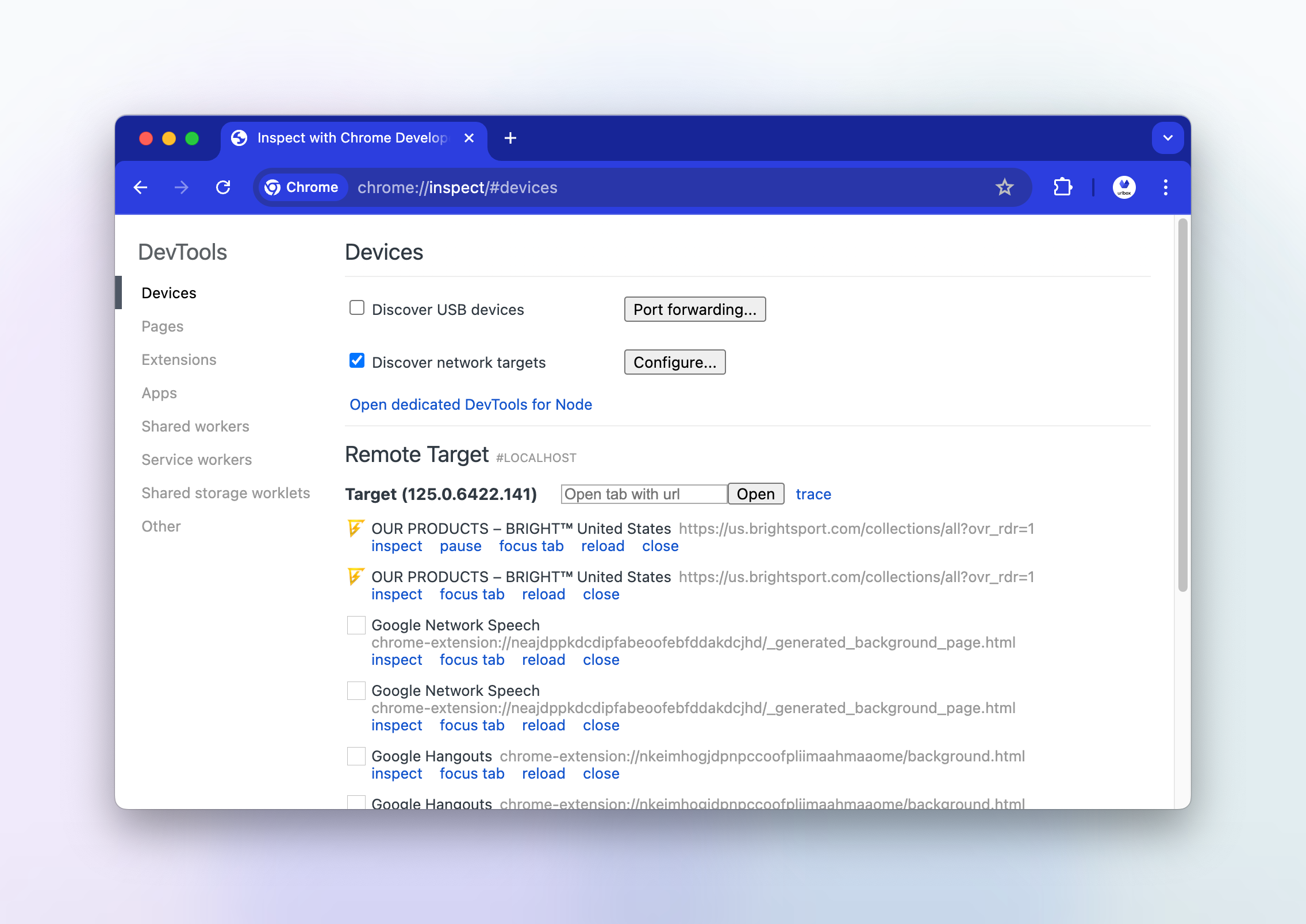
We can see how the website looks, and observe that the images are not loaded.
In the console, I'll try to run window.lazySizes.init() to see if that makes a difference:
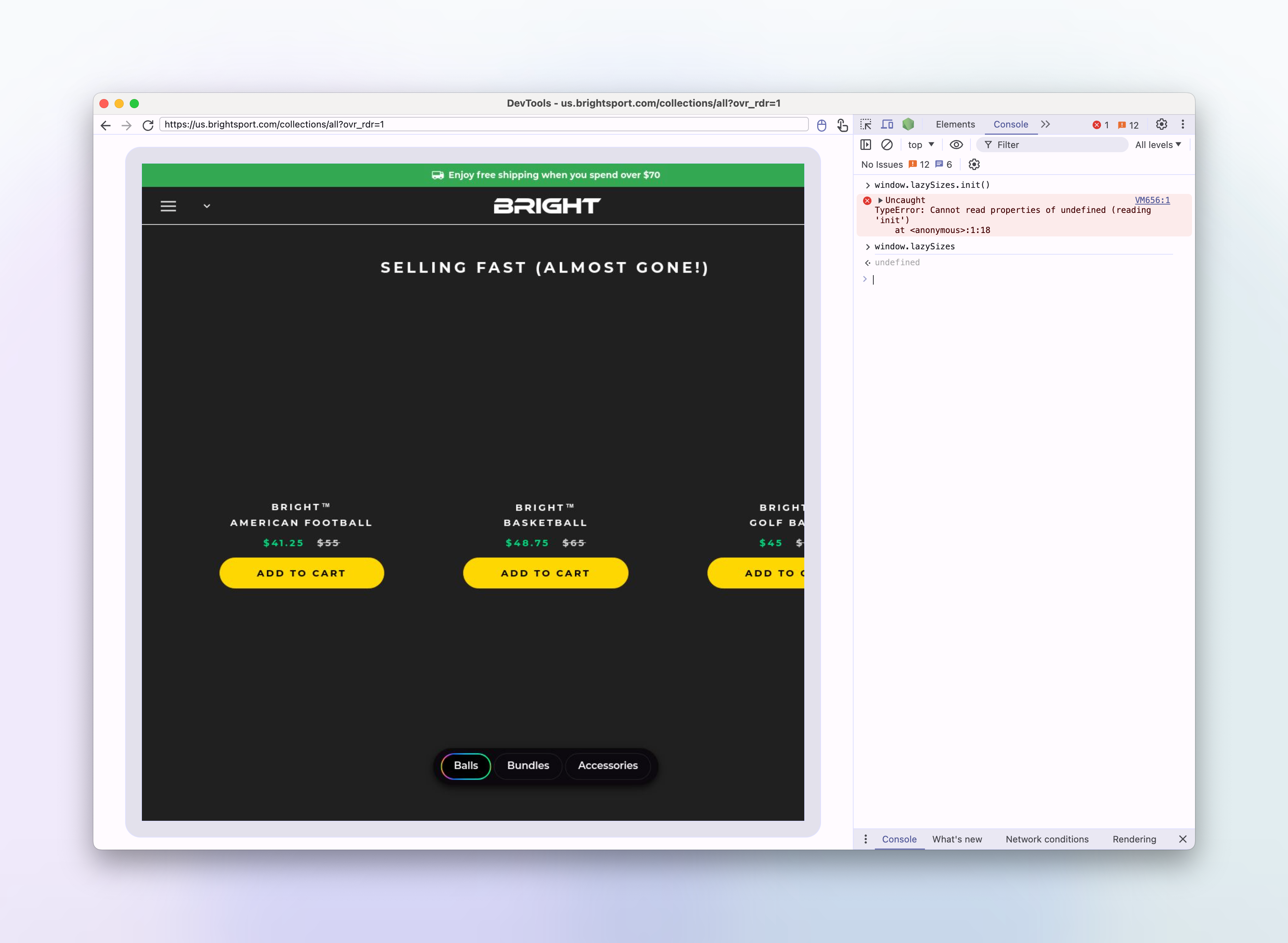
> window.lazySizes.init()
VM656:1 Uncaught TypeError: Cannot read properties of undefined (reading 'init')
at <anonymous>:1:18It looks like window.lazySizes is undefined in the remote browser. This is interesting, as we know that the lazysizes script is being loaded in the head of the html.
There are no javascript errors in the browser console, suggesting there aren't any issues executing the script. Perhaps the script isn't even being executed at all?
Let's see if jQuery or $ is available in the remote browser, since a jquery script is also referenced in the head of the html:
> jQuery
VM576:1 Uncaught ReferenceError: jQuery is not defined
at <anonymous>:1:1
(anonymous) @ VM576:1
---
> $
ƒ $() { [native code] }So it looks like the jquery script is also not loaded.
The $ here is actually a chrome devtools function that acts like an alias for document.querySelector. If it was the $ from jQuery, we wouldn't see [native code] in the printed function description.
Let's check the network tab to see if the scripts are even being downloaded:
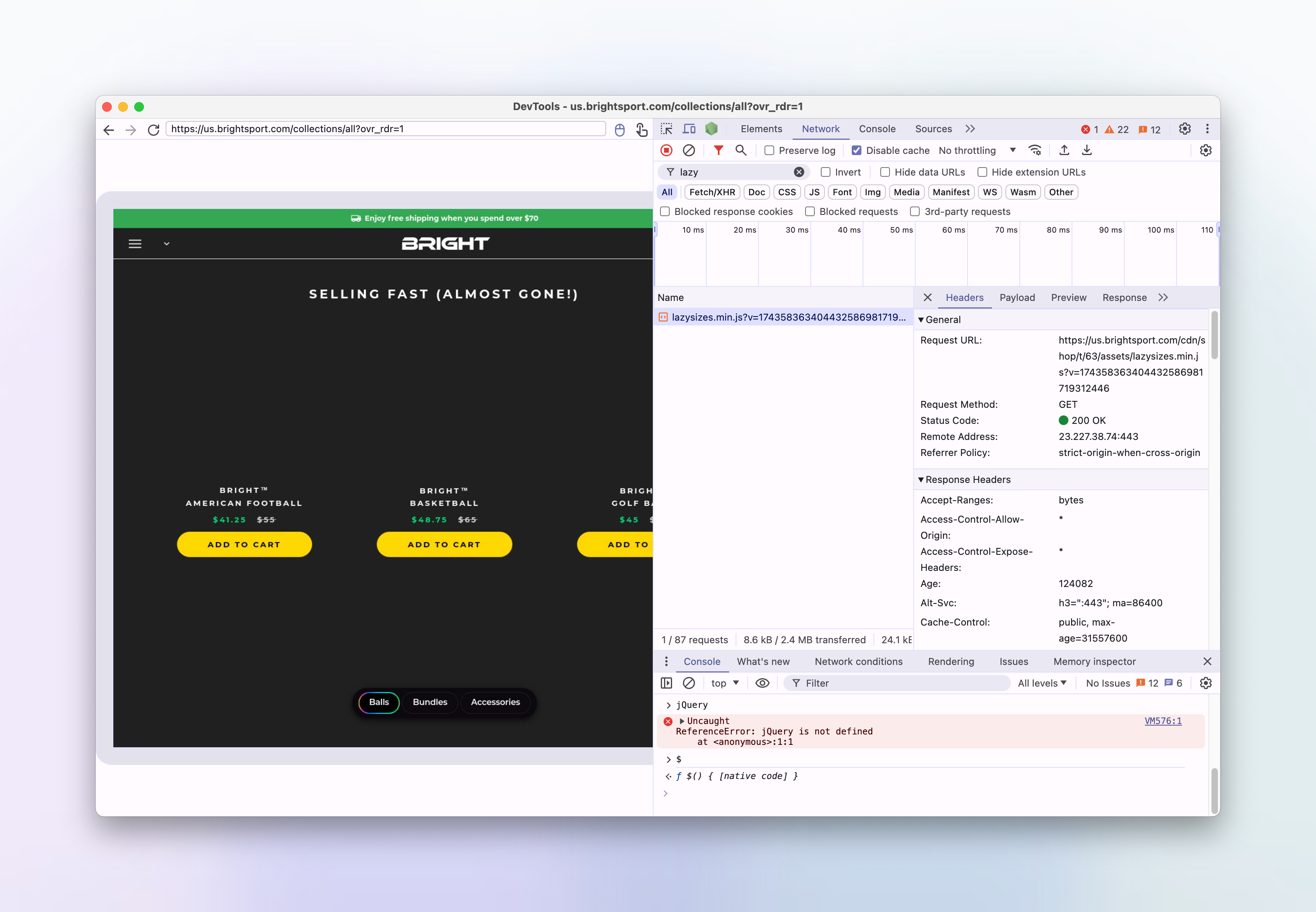
It looks like the lazysizes and jquery scripts are being downloaded, but somehow they're not being executed.
Suspicious MutationObserver scripts
Looking through some of the inline scripts in the html of the page, I'm drawn to some code which seems to be using a MutationObserver to modify the innerHTML of other script tags, it also removes the src attribute of certain script tags.
const observer = new MutationObserver((e) => {
e.forEach(({ addedNodes: e }) => {
e.forEach((e) => {
1 === e.nodeType &&
"SCRIPT" === e.tagName &&
(e.innerHTML.includes("asyncLoad") &&
(e.innerHTML = e.innerHTML
.replace(
"if(window.attachEvent)",
"document.addEventListener('asyncLazyLoad',function(event){asyncLoad();});if(window.attachEvent)"
)
.replaceAll(", asyncLoad", ", function(){}")),
e.innerHTML.includes("PreviewBarInjector") &&
(e.innerHTML = e.innerHTML.replace(
"DOMContentLoaded",
"asyncLazyLoad"
)),
e.className == "analytics" && (e.type = "text/lazyload"),
(e.src.includes("assets/storefront/features") ||
e.src.includes("assets/shopify_pay") ||
e.src.includes("connect.facebook.net")) &&
(e.setAttribute("data-src", e.src), e.removeAttribute("src")));
});
});
});
observer.observe(document.documentElement, { childList: !0, subtree: !0 });To quickly test whether this is causing the issue I can set window.MutationObserver to null and observe if it makes any difference.
In Puppeteer, we can use the page.evaluateOnNewDocument function to run scripts in the document before a page has been loaded. By setting MutationObserver to null, we can prevent them being instantiated by the page's scripts.
Let's try this:
await page.evaluateOnNewDocument(() => {
window.MutationObserver = null;
});and re-run the screenshot request:
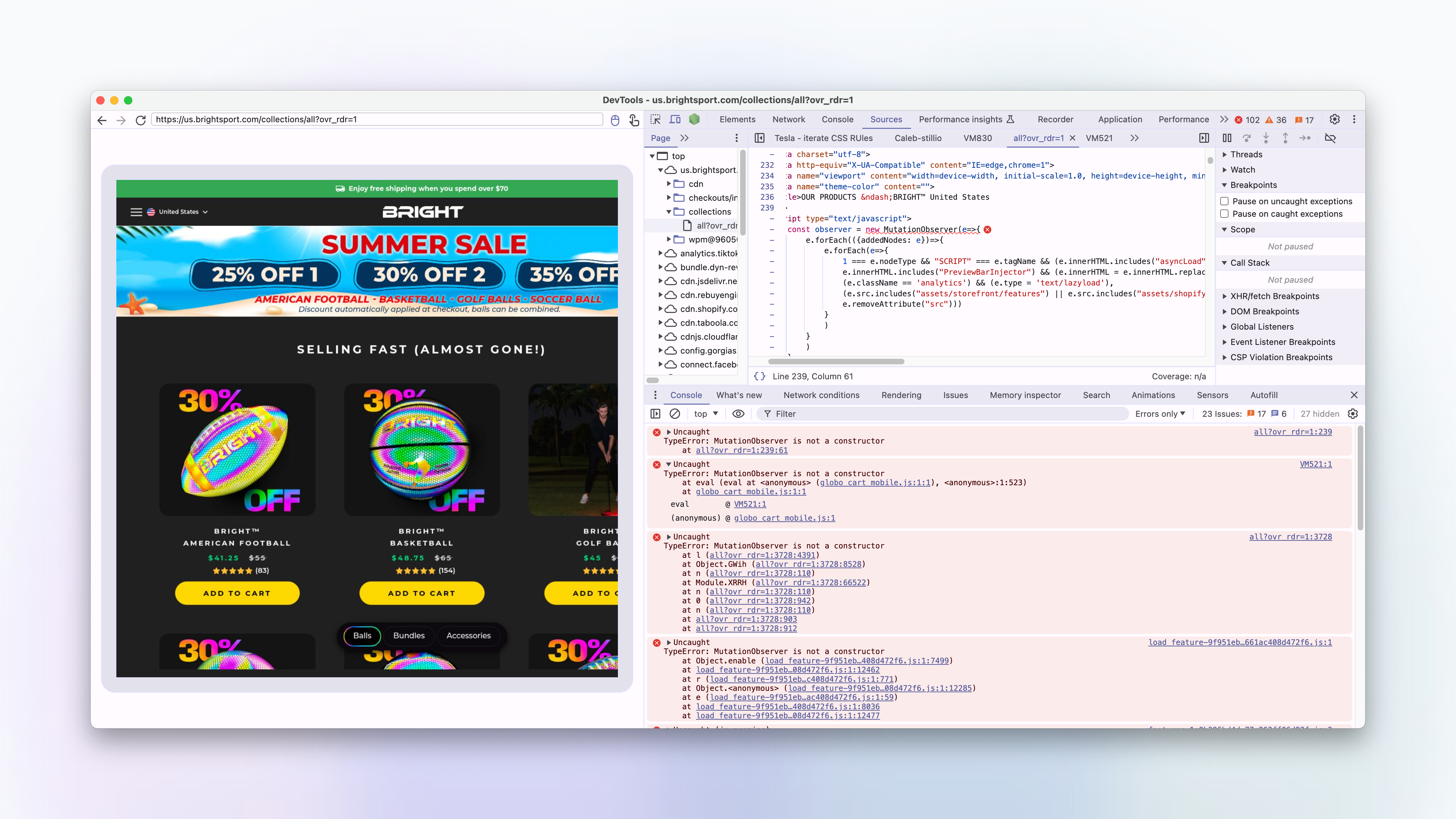
Lo and behold, the images are now loading correctly in the remote browser!
We also have quite a few TypeError: MutationObserver is not a constructor errors in the remote browser, which correspond to all of the places where a new MutationObserver is being instantiated.
By jumping to the source of each of these errors in the console, we can see how the MutationObserver is being used.
And it looks like we have found our culprit...
The second error in the console is coming from a script that looks like this:
if (navigator.platform == "Linux x86_64") {
var lazy_css = []
, lazy_js = [];
function _debounce(a, b=300) {
let c;
return (...d)=>{
clearTimeout(c),
c = setTimeout(()=>a.apply(this, d), b)
}
}
window.___mnag = "userA" + (window.___mnag1 || "") + "gent";
window.___plt = "plat" + (window.___mnag1 || "") + "form";
try {
var a = navigator[window.___mnag]
, e = navigator[window.___plt];
window.__isPSA = (e.indexOf('x86_64') > -1 && a.indexOf('CrOS') < 0),
window.___mnag = "!1",
c = null
} catch (d) {
window.__isPSA = !1;
var c = null;
window.___mnag = "!1"
}
window.__isPSA = __isPSA;
if (__isPSA)
var uLTS = new MutationObserver(e=>{
e.forEach(({addedNodes: e})=>{
e.forEach(e=>{
1 === e.nodeType && "IFRAME" === e.tagName && (e.setAttribute("loading", "lazy"),
e.setAttribute("data-src", e.src),
e.removeAttribute("src")),
1 === e.nodeType && "IMG" === e.tagName && ++imageCount > lazyImages && e.setAttribute("loading", "lazy"),
1 === e.nodeType && "LINK" === e.tagName && lazy_css.length && lazy_css.forEach(t=>{
e.href.includes(t) && (e.setAttribute("data-href", e.href),
e.removeAttribute("href"))
}
),
1 === e.nodeType && "SCRIPT" === e.tagName && (e.setAttribute("data-src", e.src),
e.removeAttribute("src"),
e.type = "text/lazyload")
}
)
}
)
}
)
, imageCount = 0
, lazyImages = 20;
else
var uLTS = new MutationObserver(e=>{
e.forEach(({addedNodes: e})=>{
e.forEach(e=>{
1 === e.nodeType && "IFRAME" === e.tagName && (e.setAttribute("loading", "lazy"),
e.setAttribute("data-src", e.src),
e.removeAttribute("src")),
1 === e.nodeType && "IMG" === e.tagName && ++imageCount > lazyImages && e.setAttribute("loading", "lazy"),
1 === e.nodeType && "LINK" === e.tagName && lazy_css.length && lazy_css.forEach(t=>{
e.href.includes(t) && (e.setAttribute("data-href", e.href),
e.removeAttribute("href"))
}
),
1 === e.nodeType && "SCRIPT" === e.tagName && (lazy_js.length && lazy_js.forEach(t=>{
e.src.includes(t) && (e.setAttribute("data-src", e.src),
e.removeAttribute("src"))
}
),
e.innerHTML.includes("asyncLoad") && (e.innerHTML = e.innerHTML.replace("if(window.attachEvent)", "document.addEventListener('asyncLazyLoad',function(event){asyncLoad();});if(window.attachEvent)").replaceAll(", asyncLoad", ", function(){}")),
(e.innerHTML.includes("PreviewBarInjector") || e.innerHTML.includes("adminBarInjector")) && (e.innerHTML = e.innerHTML.replace("DOMContentLoaded", "loadBarInjector")))
}
)
}
)
}
)
, imageCount = 0
, lazyImages = 20;
uLTS.observe(document.documentElement, {
childList: !0,
subtree: !0
})
}This semi-obfuscated script is using a MutationObserver to remove the src attribute of script tags, but only if the navigator.platform is Linux x86_64.
According to MDN:
The Navigator interface represents the state and the identity of the user agent. It allows scripts to query it and to register themselves to carry on some activities.
A Navigator object can be retrieved using the read-only window.navigator property.
Clearly, this code won't run on our local machines, as the navigator.platform will be MacIntel or similar.
If we can get our headless browsers to report their navigator.platform as something other than Linux x86_64, then this code won't run in production either.
A simple way to do this is to use the page.evaluateOnNewDocument function again this time to set navigator.platform to MacIntel:
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator.__proto__, "platform", {
get: () => "MacIntel",
});
});Let's remove the code which disables the MutationObserver and re-run the screenshot request with the changed navigator.platform:
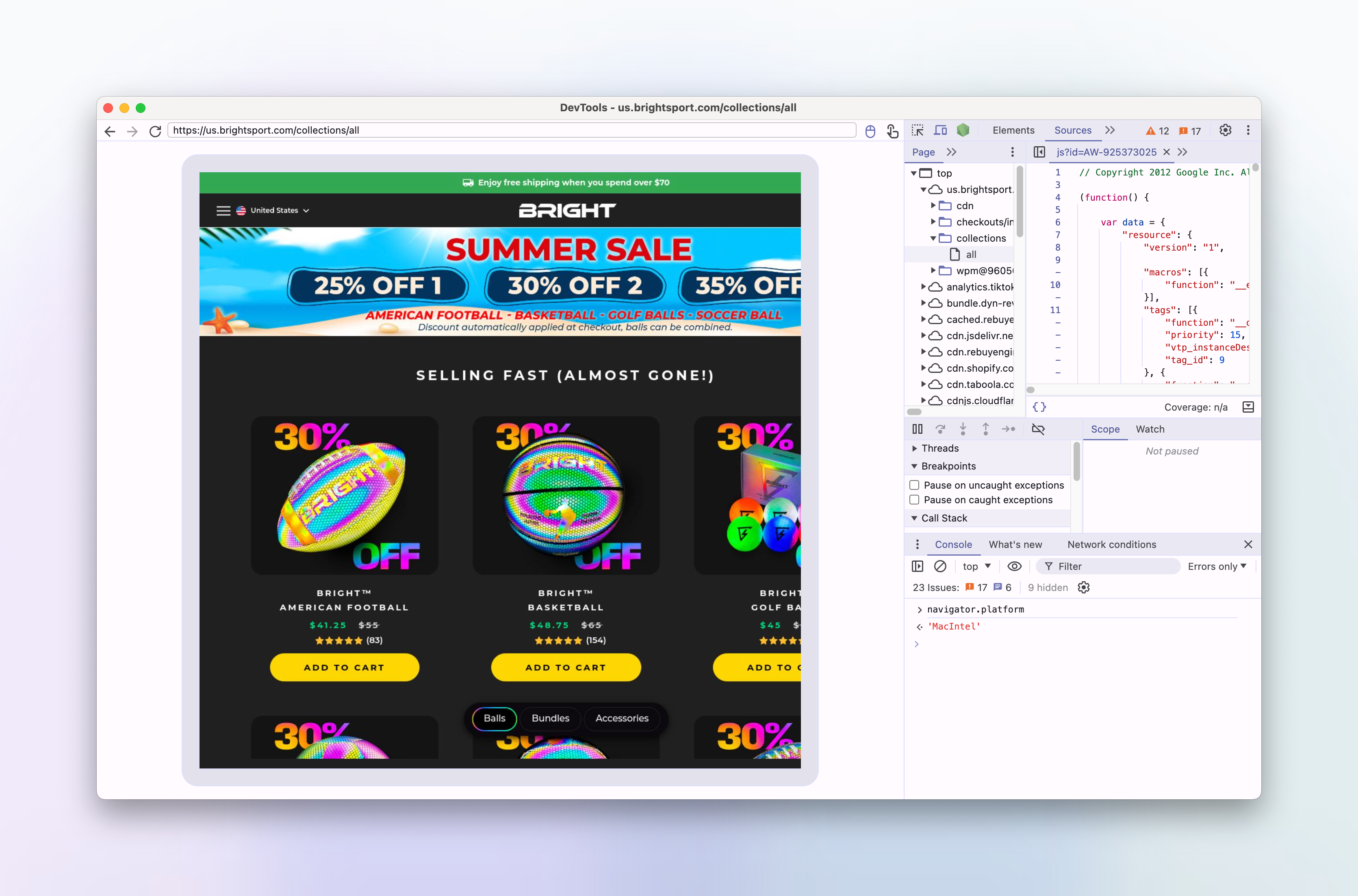
Yes, the images are now loading correctly in the remote browser!
We will now turn this into a permanent fix by adding the navigator.platform override to our rendering code. We'll also make it an api option that can be set and overridden by the user, we'll default the value to MacIntel, so that our headless browsers don't get hit by these kinds of workarounds in the future.
The problem is solved, but I still want to understand why a website would want to disable scripts based on a navigator.platform of Linux x86_64.
Shopify plugins and faking performance metrics
A google for 'shopify scripts linux x86_64' brings up quite a few results, especially this one from shopify's performance blog titled "Don't get scammed by fake performance experts and apps" which mentions that some shopify plugins and developers are purposely disabling scripts for linux based visitors in order to make their site appear faster in performance testing tools such as Google's Lighthouse:
We uncovered a set of apps and fake experts cheating the performance metrics. We found those practices in almost 15% of extensions that promised one-click optimizations. This means that a large number of merchant sites are affected.
The main trick is to add a script that detects if the page is loaded using a speed testing tool. It then prevents the browser from loading most resources. These lighter pages achieve better scores, which help convince merchants that their money is well spent. However, no real improvement is achieved with real users meaning that visitors are still impacted by poor performance.
and further down in the article, the exact technique used on this very shopify site is mentioned:
The most popular practices include:
- Trying to prevent the loading of subsequent resources using the Yett library or MutationObserver directly.
The
navigator.platformproperty contains a string that identifies the platform on which the browser is running. At some point, performance cheaters decided that looking for the Linux x86_64 value would be a good enough detection technique. Linux is often used for servers and has a small user base compared to other operating systems. This way, they can detect all tools running in data centers, not only the most popular ones. Of course this means that any human using Linux would also be affected.
So it looks like the owner of this shopify site has installed an extension which is disabling scripts for linux based visitors in an attempt to make their site appear faster to performance testing tools.
An unfortunate side effect for Urlbox users meant that this shopify performance hack also prevents some shopify sites from loading correctly in urlbox's renderer, meaning the screenshots were not as accurate as we would like them to be.
Finding the plugin
What's interesting about the particular script that causes this is that it is not coming directly from a file, as can be seen by the VM521:1 in the console.
The script is being eval'd by another script file. That offending script, is a file called globo_cart_mobile.js which contains this code:
eval(function(p, a, c, k, e, r) {
e = function(c) {
return (c < a ? '' : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))
}
;
if (!''.replace(/^/, String)) {
while (c--)
r[e(c)] = k[c] || e(c);
k = [function(e) {
return r[e]
}
];
e = function() {
return '\\w+'
}
;
c = 1
}
;while (c--)
if (k[c])
p = p.replace(new RegExp('\\b' + e(c) + '\\b','g'), k[c]);
return p
}('l(r.O=="P y"){i j=[],s=[];u Q(a,b=R){S c;T(...d)=>{U(c),c=V(()=>a.W(X,d),b)}}2.m="Y"+(2.z||"")+"Z";2.A="10"+(2.z||"")+"11";12{i a=r[2.m],e=r[2.A];2.k=(e.B(\'y\')>-1&&a.B(\'13\')<0),2.m="!1",c=C}14(d){2.k=!1;i c=C;2.m="!1"}2.k=k;l(k)i v=D E(e=>{e.8(({F:e})=>{e.8(e=>{1===e.5&&"G"===e.6&&(e.4("n","o"),e.4("f-3",e.3),e.g("3")),1===e.5&&"H"===e.6&&++p>q&&e.4("n","o"),1===e.5&&"I"===e.6&&j.w&&j.8(t=>{e.7.h(t)&&(e.4("f-7",e.7),e.g("7"))}),1===e.5&&"J"===e.6&&(e.4("f-3",e.3),e.g("3"),e.15="16/17")})})}),p=0,q=K;18 i v=D E(e=>{e.8(({F:e})=>{e.8(e=>{1===e.5&&"G"===e.6&&(e.4("n","o"),e.4("f-3",e.3),e.g("3")),1===e.5&&"H"===e.6&&++p>q&&e.4("n","o"),1===e.5&&"I"===e.6&&j.w&&j.8(t=>{e.7.h(t)&&(e.4("f-7",e.7),e.g("7"))}),1===e.5&&"J"===e.6&&(s.w&&s.8(t=>{e.3.h(t)&&(e.4("f-3",e.3),e.g("3"))}),e.9.h("x")&&(e.9=e.9.L("l(2.M)","N.19(\'1a\',u(1b){x();});l(2.M)").1c(", x",", u(){}")),(e.9.h("1d")||e.9.h("1e"))&&(e.9=e.9.L("1f","1g")))})})}),p=0,q=K;v.1h(N.1i,{1j:!0,1k:!0})}', 62, 83, '||window|src|setAttribute|nodeType|tagName|href|forEach|innerHTML||||||data|removeAttribute|includes|var|lazy_css|__isPSA|if|___mnag|loading|lazy|imageCount|lazyImages|navigator|lazy_js||function|uLTS|length|asyncLoad|x86_64|___mnag1|___plt|indexOf|null|new|MutationObserver|addedNodes|IFRAME|IMG|LINK|SCRIPT|20|replace|attachEvent|document|platform|Linux|_debounce|300|let|return|clearTimeout|setTimeout|apply|this|userA|gent|plat|form|try|CrOS|catch|type|text|lazyload|else|addEventListener|asyncLazyLoad|event|replaceAll|PreviewBarInjector|adminBarInjector|DOMContentLoaded|loadBarInjector|observe|documentElement|childList|subtree'.split('|'), 0, {}))This is clearly a very obfuscated script which when run will evaluate into the slightly less obfuscated script from above.
It looks like this is from a plugin developer named globo based in Vietnam. Here are some of their shopify apps listed in the app store: https://apps.shopify.com/partners/globo
A search on github for the string __isPSA also brings up very similar looking scripts, and a lot of liquid templates, so it seems like this technique has been copied and pasted into multiple shopify plugins:
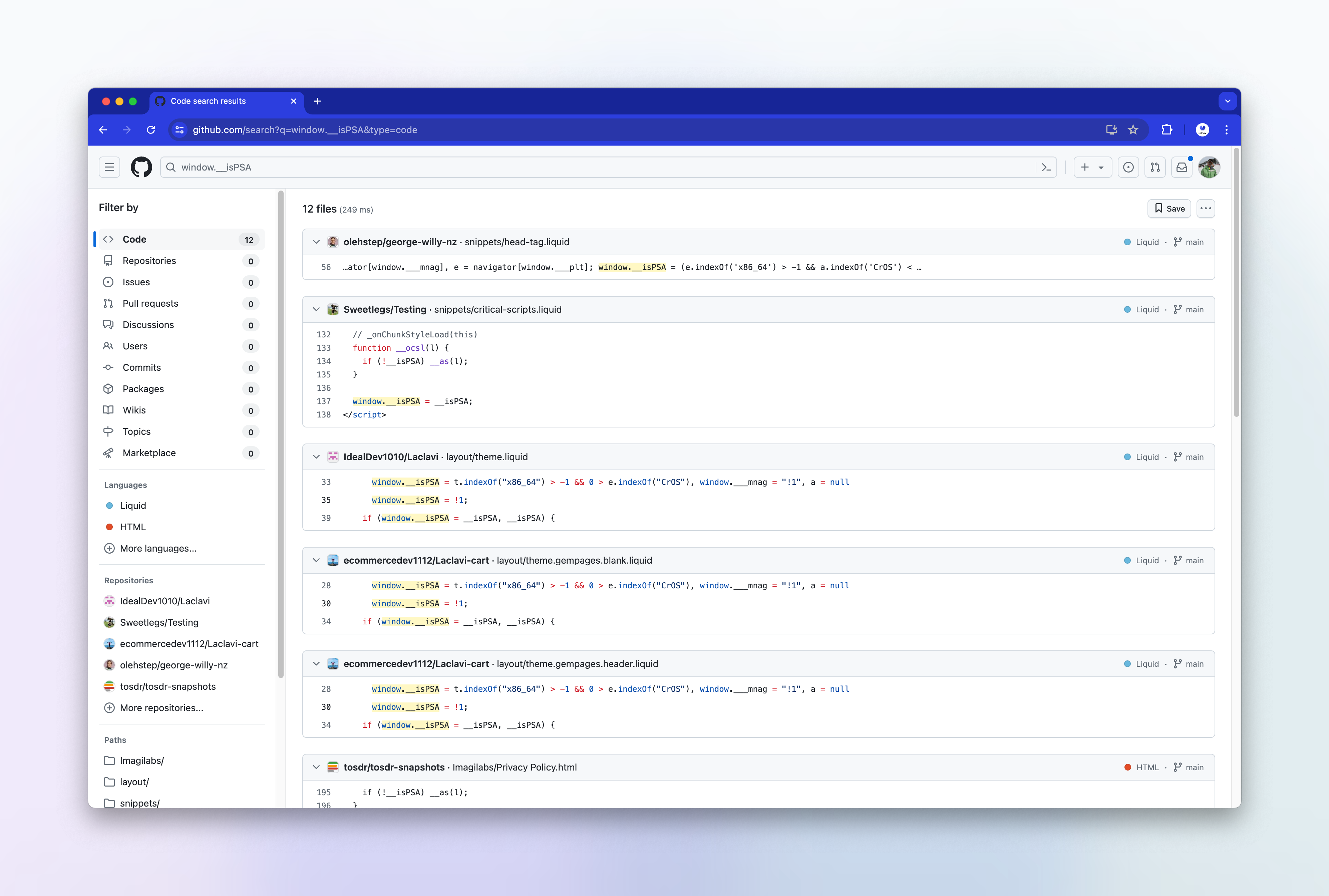
Testing the fix on the other shopify site
We can now test the fix on the other shopify site that the customer reported was having a similar loading issue. We'll set the navigator.platform to Linux x86_64 and re-run the screenshot request:
and now with the navigator.platform set to MacIntel:
So it appears that this site also had a similar plugin installed, and the platform fix works for this site too.
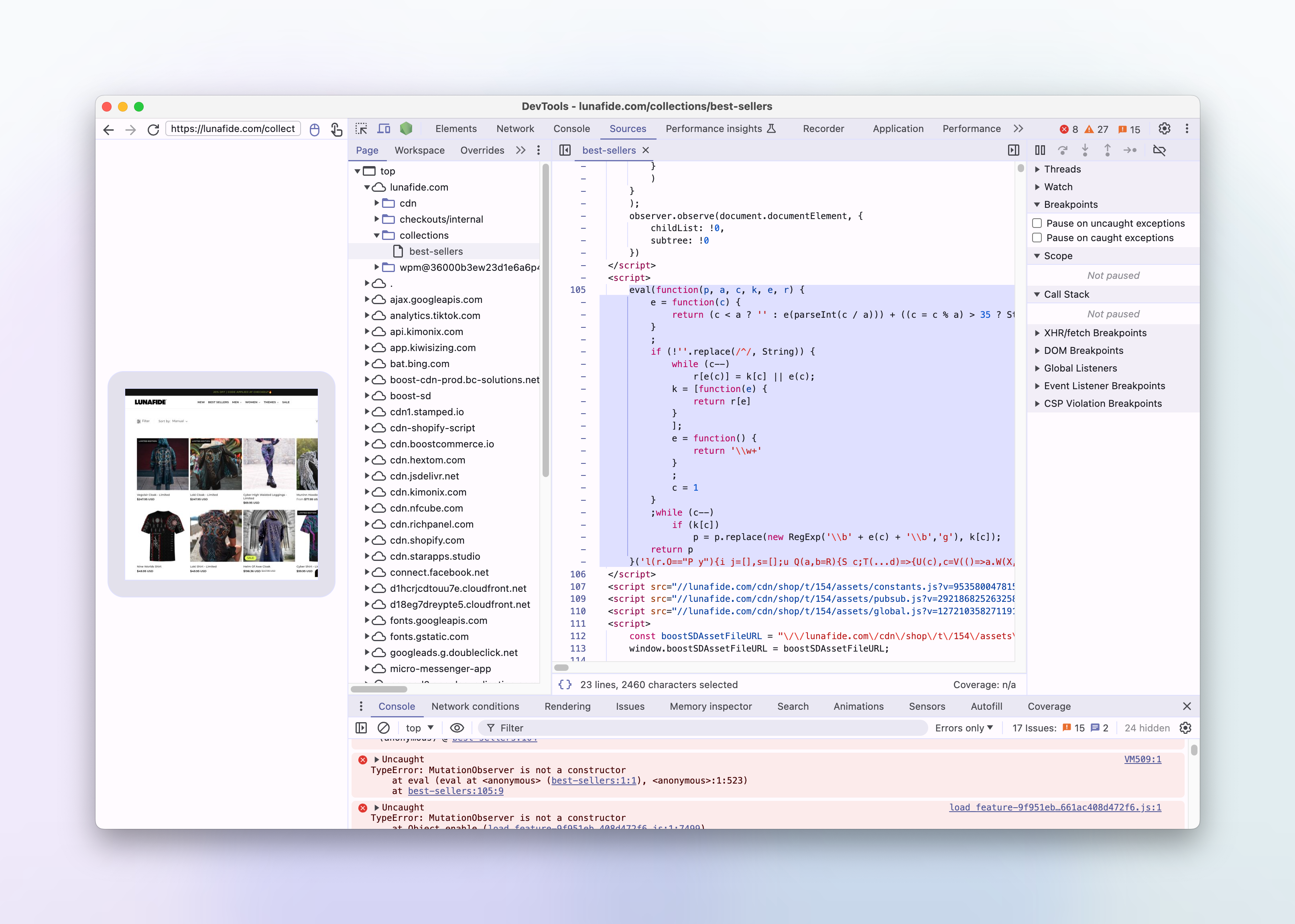
Out of interest, I disabled the MutationObserver again in order to track down which script contained the performance hack. It turns out that the obfuscated code snippet is exactly the same here as it was on the other site, and it appears that it's been copied and pasted directly into the html <head>:
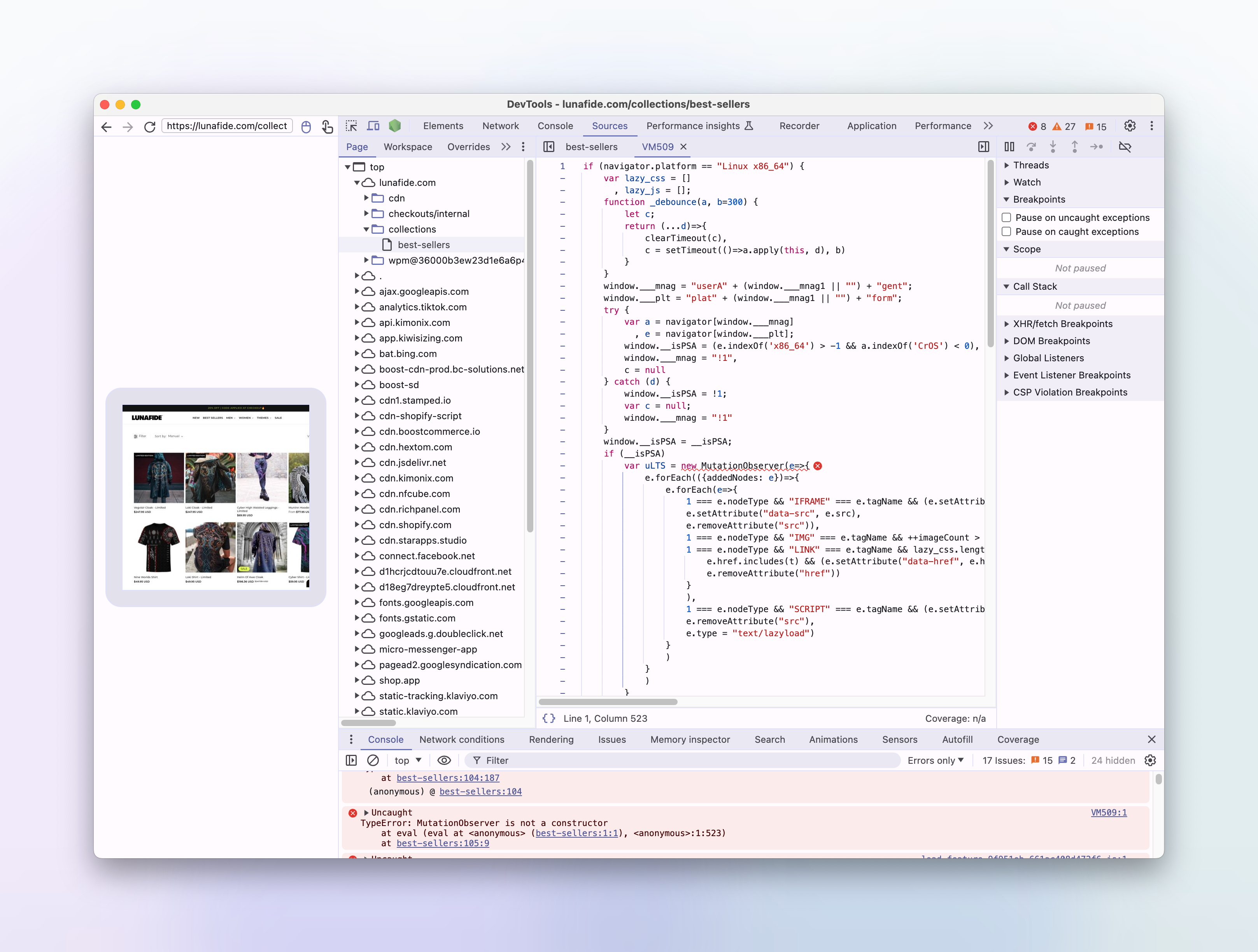
and when executed, becomes the same performance hack, relying on navigator.platform sniffing:
Conclusion
In this article we've seen how we debugged a platform specific issue with a customer's screenshots, whereby images were not loading correctly and the site appeared to not have loaded.
We went down many rabbit holes and got fooled by lots of red herrings.
We used a combination of local development, remote debugging in a production-like environment, and inspecting the source of the website to find the root cause of the issue, which was caused by a rogue shopify plugin disabling scripts from loading if the browsers host platform was linux based.
In the end the fix was quite simple, by overriding the navigator.platform property in the Urlbox headless browser, we were able to prevent scripts being disabled by the plugin, which meant the images on the page could now be lazy loaded correctly and start showing again.
By fixing this issue, we also introduced a new option to our screenshot api: platform which allows Urlbox users to set the navigator.platform property to a value of their choosing.