
We are specialists at taking automated screenshots. We've been rendering for more than 10 years, and so have a wealth of experience ironing out interesting edge cases, often with E-Commerce sites. Recently I found that when trying to render a particular site with our full_page option, our renderer couldn't find an element at the top of the page.
I thought I understood the DOM–until I found its Shadow.
The Issue
One challenge when capturing a screenshot in full-page mode is simulating a natural scrolling experience while avoiding the inclusion of sticky elements that should move with the page.
Our approach ensures that elements fixed to the top (e.g., menu banners) remain at the top, while those positioned at the bottom (e.g., chatbot buttons, back-to-top buttons) stay anchored at the bottom. We do this by taking many screenshots, then 'stitching' them together. Here's more information on our full-page 'modes'.
The site that caused us an issue showed the following during a 'stitch' style full page render:

As we approach our second shot which we intend to stitch to the first, the sticky banner is still visible, resulting in a strange looking screenshot with a duplicated banner!
Investigating
Like any good developer, I opened Chrome DevTools and started inspecting the HTML. After replicating the issue locally, I noticed that the list of fixed elements we find and perform business logic on did not include the culprit.
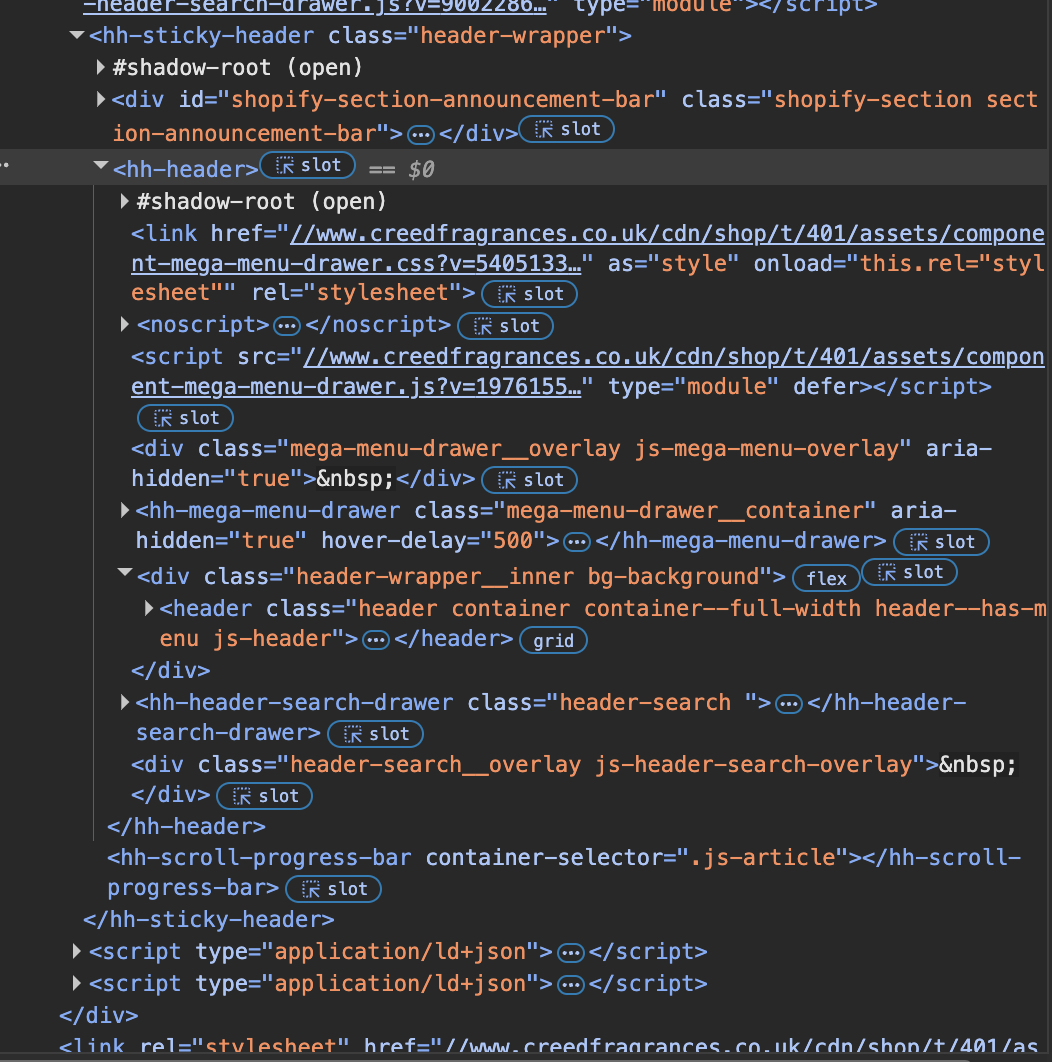
I found some strangely named HTML elements, I had never heard of a <hh-header> before... I realised it was a custom element, with a shadow DOM inside of it.
In short, the Shadow DOM is like a hidden layer of the DOM where elements can exist separately from the main document while still being attached to it. The shadow root serves as the entry point to this hidden layer and is attached to a shadow host—the visible element in the main DOM that contains the shadow root.
The Shadow DOM can be created in either open or closed mode:
- Open: The shadow root can be accessed using
shadowHostElement.shadowRootfrom JavaScript. - Closed: The shadow root is inaccessible from outside the component.
In this case our host is <hh-header>, our shadow root lives inside of it #shadow-root (open), and our culprit is a fixed position div inside of it.
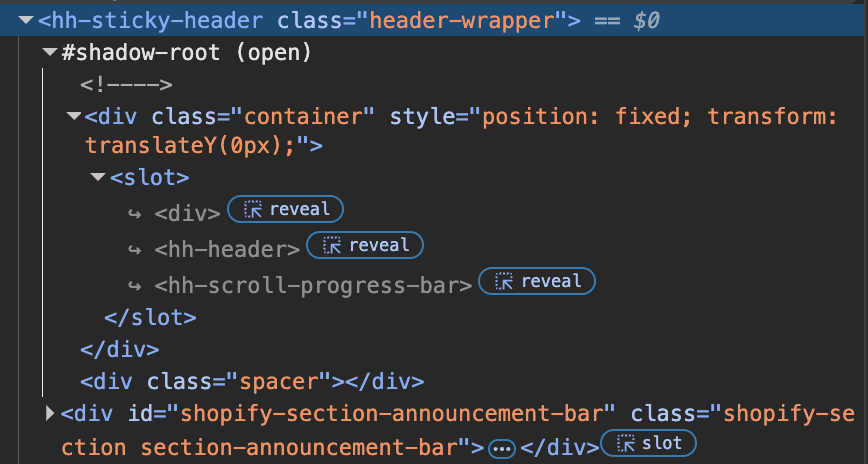
For a deeper understanding which includes what <slot> elements are, check out MDN's explanation.
Solution
Fortunately, this banner’s Shadow DOM is open, as indicated by #shadow-root (open) in the screenshot above. This means we can access its elements using JavaScript.
Now, let’s say you’re filtering elements to find those with position: fixed, but you also need to account for elements inside an open Shadow DOM—like in this example. You can do that by simply retrieving all shadow DOM elements before applying your filter:
let shadowDomElements: Element[] = [];
allElements
.filter((element) => element.shadowRoot)
.forEach((element) => {
shadowDomElements = [
...shadowDomElements,
...(element.shadowRoot?.querySelectorAll("*") || []),
];
});This collects all elements within shadow roots across the page. Including these in our list of fixed elements solved the issue immediately.

Conclusions
The Shadow DOM really isn’t as mystical as it seems—it’s just another tool for building reusable components while abstracting logic. However, when working with automation tools like Puppeteer, it introduces an extra layer of complexity that can lead to unexpected rendering issues if not accounted for.
In cases like this, where elements are hidden inside an open shadow root, simply expanding your element selection to include shadow DOM children can resolve the issue. However, if the shadow root is closed, things get trickier, as there’s no direct way to access its contents through JavaScript.
This experience reinforced a valuable lesson: even when you think you fully understand the DOM, there’s always something new lurking in the shadows.
Taking Screenshots the easier and more reliable way
At Urlbox, we've already worked through the headaches you might be facing when trying to take screenshots of websites, HTML and PDFs.
We have a whole host of options that make it easy to get going, including waiting for elements on the page.
We also offer AI prompts, Cloud storage, No code integrations with Zapier, taking screenshots through proxies, and a range or other features that could save you time and hassle.
Sign up for our free trial and give our sandbox a try, or contact us directly, and we can help you find the answers you're looking for ✌️.