
Converting an HTML document to PDF allows you to, at minimum, view the document offline, but some advanced PDF readers allow you to edit, highlight, strikethrough, and comment in the PDF as well. PDFs are superior to HTML documents when it comes to sharing (not to mention printing, should the need for a hard copy arise) because their formatting stays consistent regardless of the device you use to view them.
There are lots of tools on the market that make it relatively easy to convert your HTML documents and web pages to PDF—some are free to use, some are open source, and some have good community support. Let’s take a look at a few, so you can come to your own conclusions about which methods would best serve your needs.
pdfkit
pdfkit is a Python wrapper library for wkhtmltopdf`. This library has a relatively simple-to-use API; you can integrate it into a much bigger software project or as part of an automation script to generate PDFs from HTML documents or web pages.
Installation
Since pdfkit relies on wkhtmltopdf under the hood, you need to install wkhtmltopdf first.
For Debian/Ubuntu users:
sudo apt-get install wkhtmltopdfFor macOS users:
brew install homebrew/cask/wkhtmltopdfWindows users can download the installer from wkhtmltopdf. After a successful installation, you can go ahead and install pdfkit via pip or pip3 (for Python3 users).
pip3 install pdfkitUsage
After you’ve successfully installed pdfkit, you can write the script for converting HTML to PDF. pdfkit gives you the option of three HTML sources:
- For HTML text or string source:
pdfkit.from_string - For HTML file source:
pdfkit.from_file - For a URL source:
pdfkit.from_url
Here’s a sample script to illustrate how pdfkit works; just for the fun of it, let’s assume that I’m researching some of the world's biggest entrepreneurs.
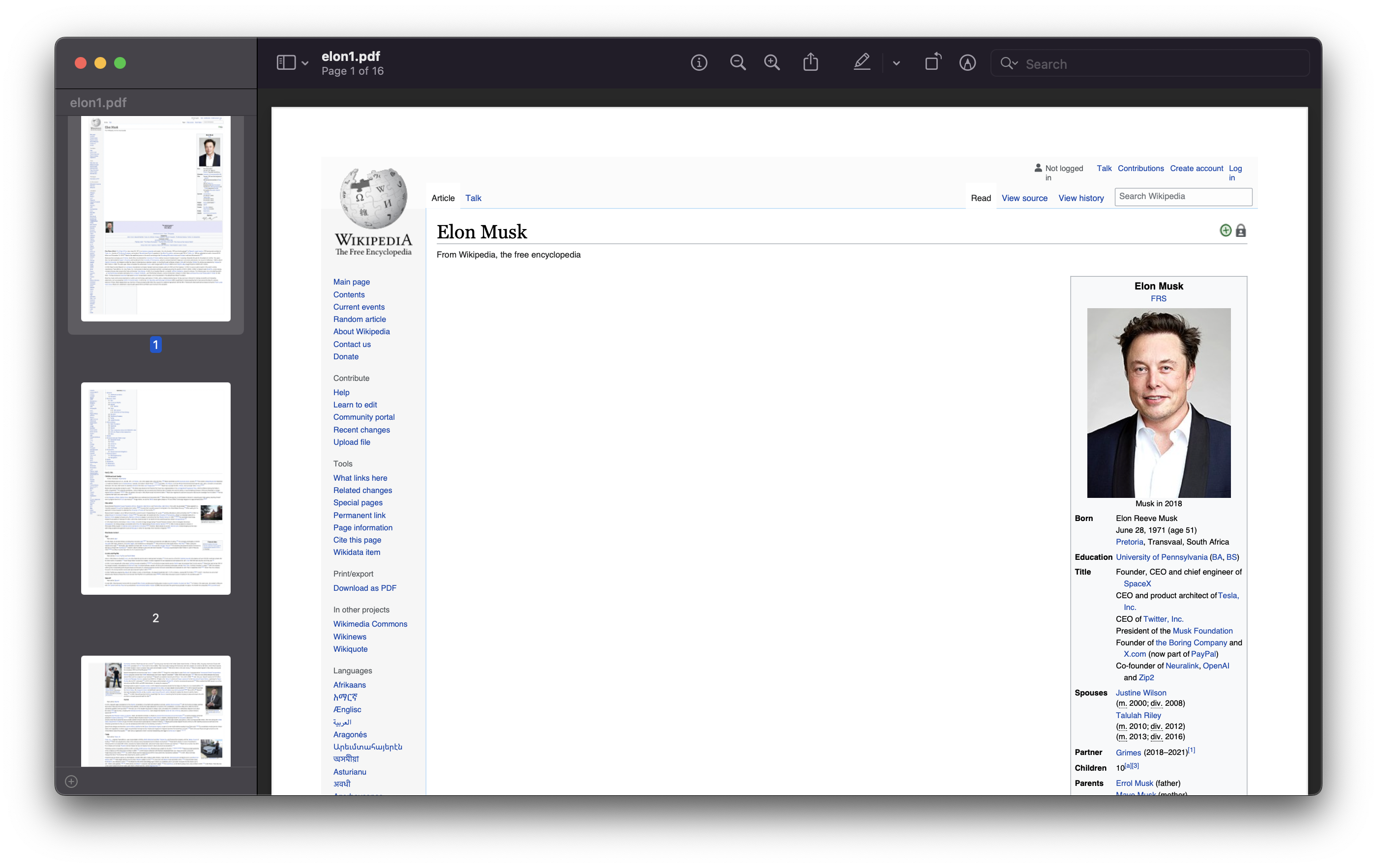
import pdfkit
pdfkit.from_url("https://en.wikipedia.org/wiki/Elon_Musk", "elon1.pdf")And here's an image of the resulting PDF:
pyhtml2pdf
pyhtml2pdf is a simple python wrapper to convert HTML to PDF with headless Chrome via Selenium.
Installation
pyhtml2pdf depends on an installation of the Chrome browser or ChromeDriver. After making sure that either is installed, proceed to install the pyhtml2pdf Python package.
pip3 install pyhtml2pdfUsage
After a successful installation of pyhtml2pdf, go ahead and write a Python script to convert an HTML document to PDF.
Let’s continue with the Wikipedia example in the previous example and create a file called script.py.
from pyhtml2pdf import converter
converter.convert("https://en.wikipedia.org/wiki/Elon_Musk", "elon2.pdf")python3 script.pyAfter running the script, I got this output:

DocRaptor
Unlike the previous tools we’ve covered, DocRaptor is a cloud-based service. Thanks to a robust infrastructure, it should be able to handle a large number of requests and conversions. Docraptor also gives you the ability to add headers, footers, page breaks, page numbers, and a table of contents to your final PDF.
DocRaptor is not an entirely free service, although it does have a free tier in its subscription plan. However, note that the free tier allows only five conversions per month.
To get started with DocRaptor, create an account with the free tier subscription plan. DocRaptor also provides an SDK for popular platforms and programming languages such as PHP, Python, Node, Ruby, Java, .Net, and JQuery.
Installation
After creating your DocRaptor account, you’ll need to install the SDK; this example uses the Python SDK.
pip3 install --upgrade docraptorAfter running the above successfully, DocRaptor should be installed.
Usage
Now that you have DocRaptor installed, the next step is to write the script that will interact with DocRaptor’s web service through their API.
import docraptor
doc_api = docraptor.DocApi()
doc_api.api_client.configuration.username = "<API_KEY>"
response = doc_api.create_doc({
"test": False,
"document_url": "https://en.wikipedia.org/wiki/Elon_Musk",
"name": "elon3.pdf",
"document_type": "pdf"
})After writing and running this sample script, you should see your conversion history on your document history page.
python3 script.py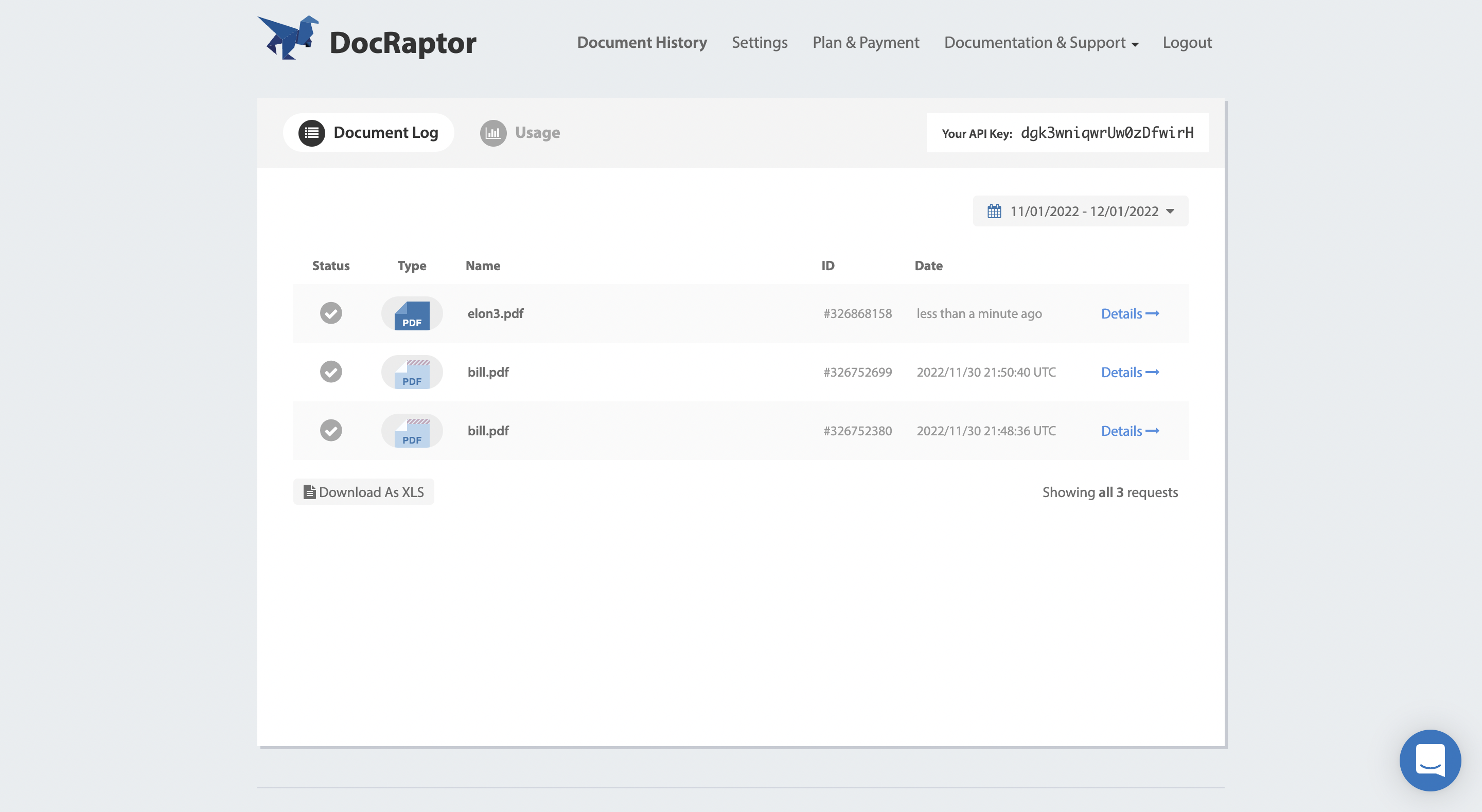
Click Details to see more about a particular conversion.
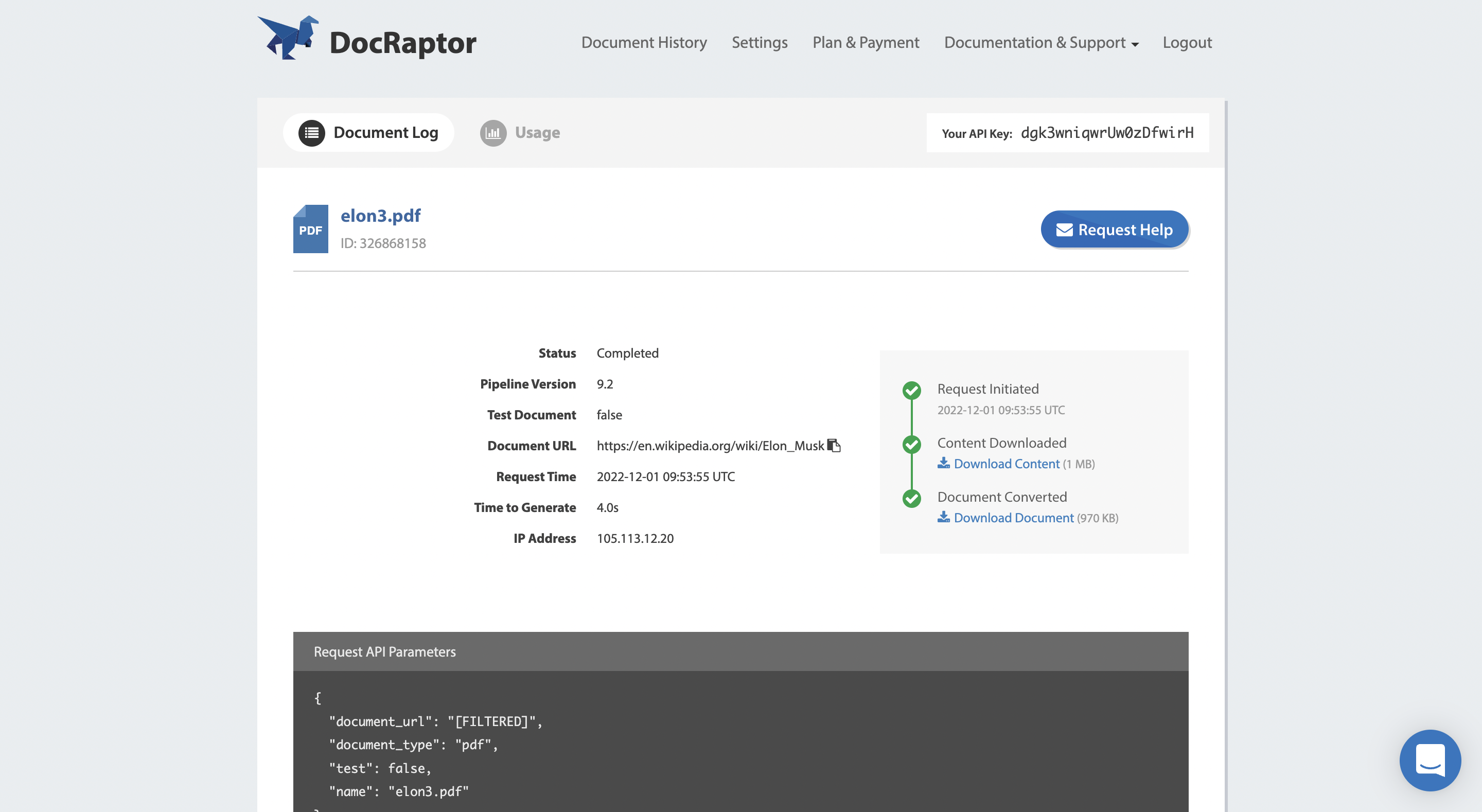
From the conversion timeline on the right side of the page, click the download link to download your converted PDF.
Urlbox
Urlbox is a service that handles a lot of edge cases inherent to complex web pages and HTML documents, so it offers a lot of customization to achieve your desired result. It not only allows you to convert HTML and URLs to PDFs, but images as well.
First, create a free account and get your API key. Next, log into your new Urlbox account and navigate to the dashboard.
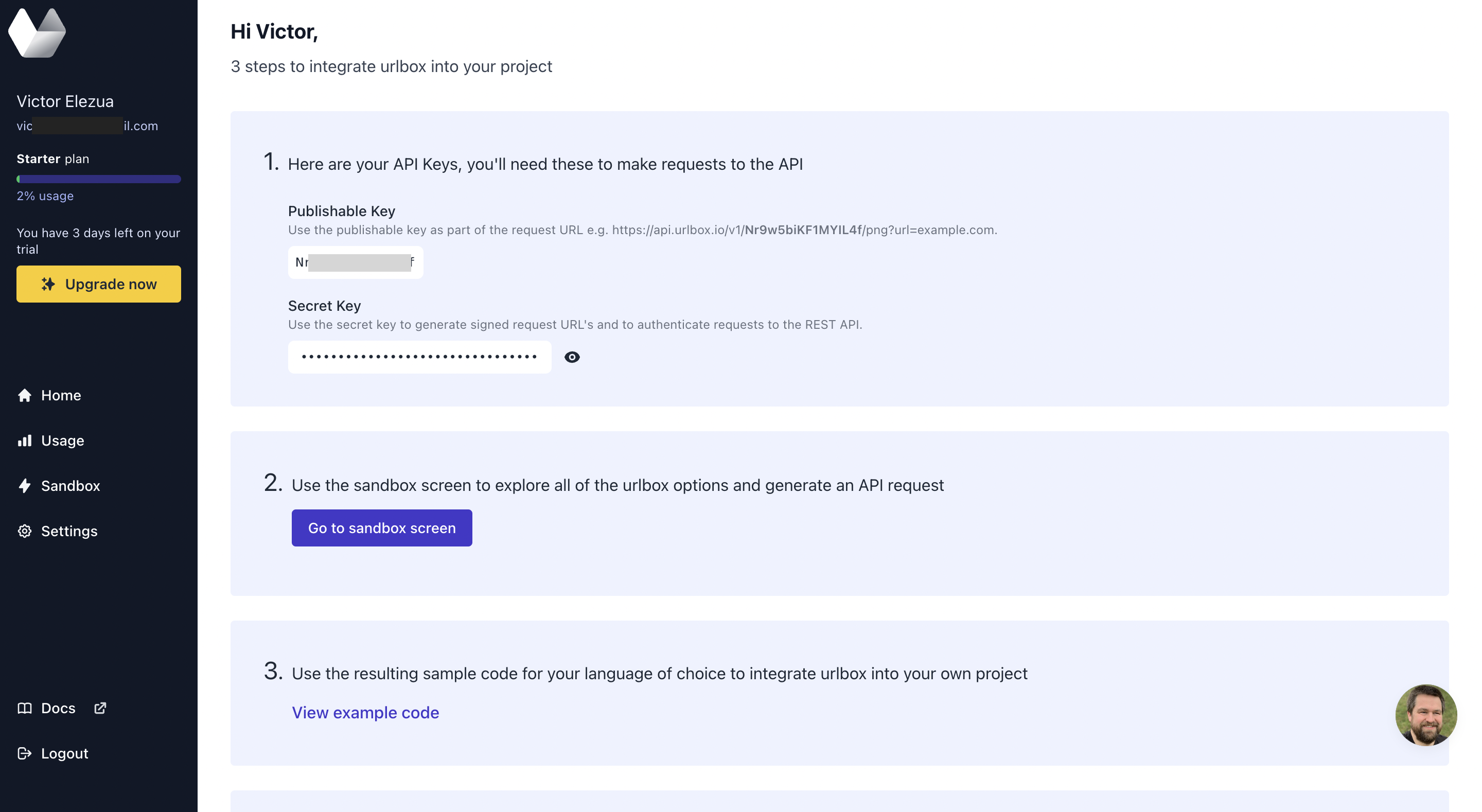
In your dashboard, you will see your publishable and secret API keys for making requests to the Urlbox API.
Installation
The next step is to install Urlbox SDK via an HTTP library with a GET request.
Usage
To start converting an HTML doc to a PDF, you first need to understand the URL structure for making requests to the Urlbox API: https://api.urlbox.com/v1/api-key/format?options.
So let’s break that down:
api-keyis the publishable key on your dashboard.formatcan be any ofpng,pdf,jpg,jpeg,avif,webp,svg,html.optionsrefers to a query string that contains all the options that you want to set.
When you send the HTTP GET request, the Urlbox API responds with the binary data of the converted PDF—or any format of your choosing with an HTTP header that has Content-Type—to a type corresponding to the format in your request. This makes the Urlbox API very flexible. You can enter your URL in your browser and get your converted PDF rendered right in your browser, ready to download.
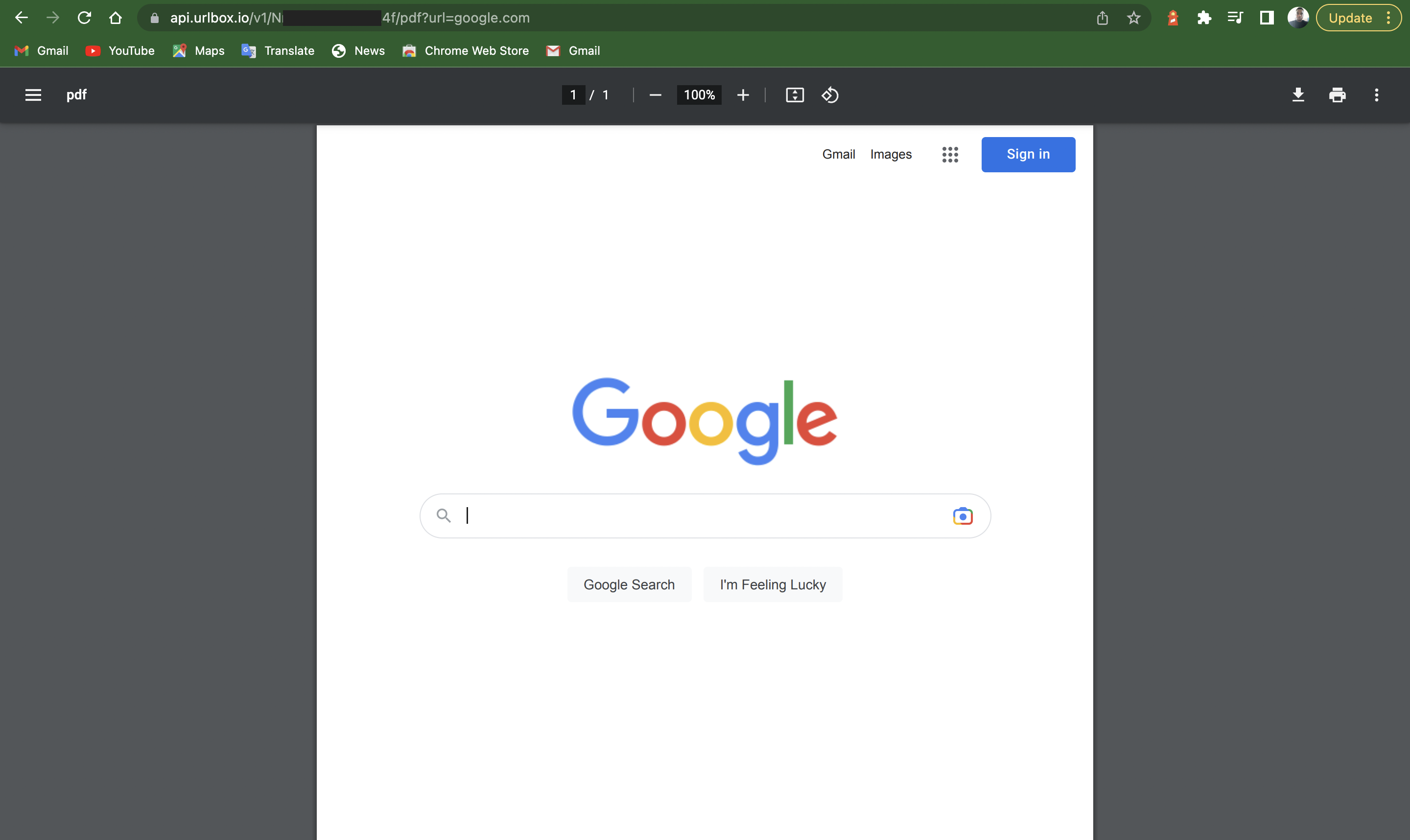
You can also write a Python script to utilize the Urlbox API. I’ll be illustrating with the script provided in Urlbox’s documentation.
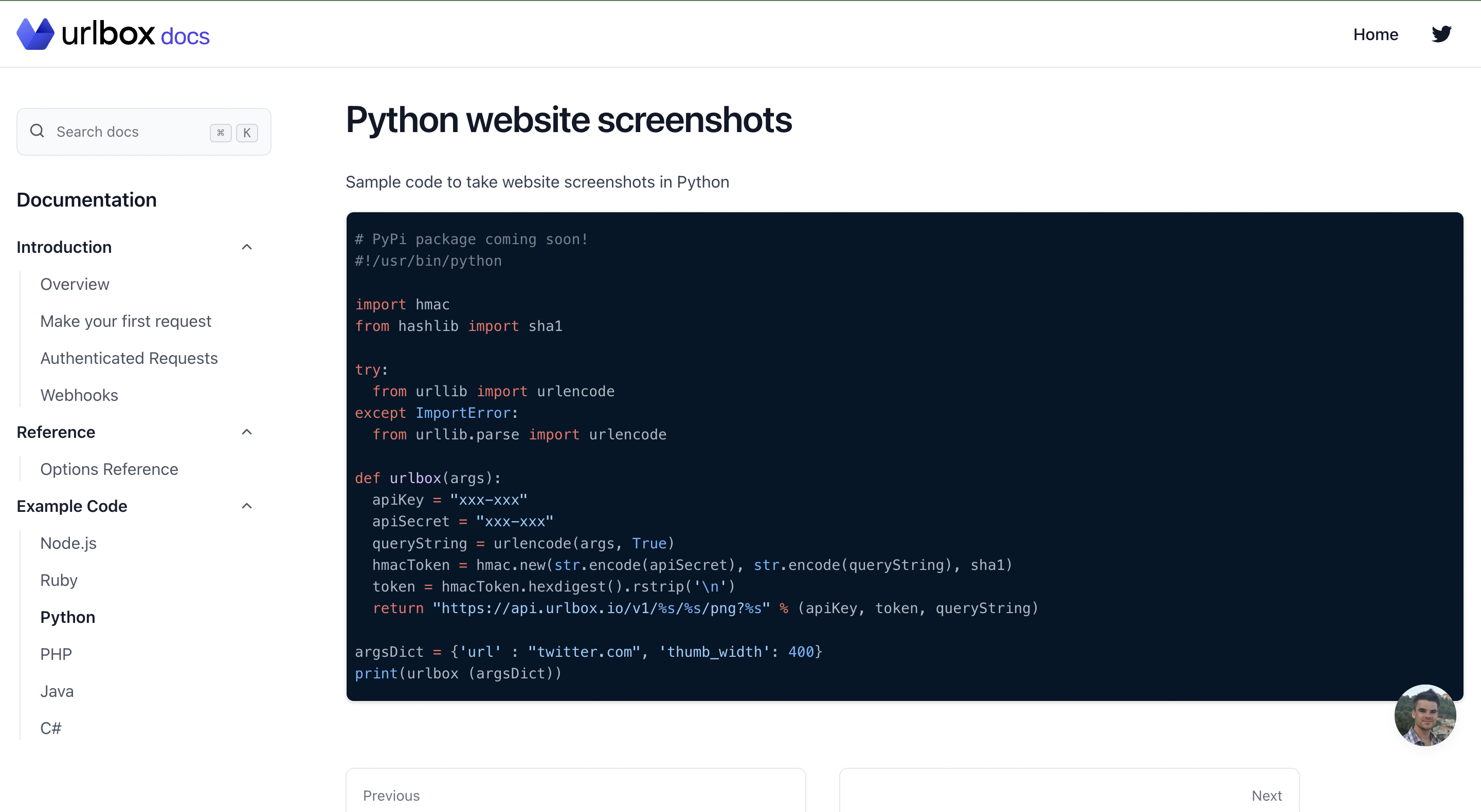
The code in the documentation illustrates how to build a query string to make a request to the Urlbox API. You’ll have to introduce the code to actually make the HTTP request.
import hmac
from hashlib import sha256
from urllib.parse import urlencode
import urllib.request
def urlbox(args):
apiKey = "<YOUR PUBLISHER KEY>"
apiSecret = "YOUR SECRET KEY"
queryString = urlencode(args, True)
hmacToken = hmac.new(str.encode(apiSecret), str.encode(queryString),
sha256)
token = hmacToken.hexdigest().rstrip('\n')
return "https://api.urlbox.com/v1/%s/%s/pdf?%s" % (apiKey, token,
queryString)
argsDict = {'url' : "https://en.wikipedia.org/wiki/Elon_Musk", 'thumb_width': 400}
print(urlbox (argsDict))
response = urllib.request.urlopen(urlbox(argsDict)).read()
In the above script, urllib is part of Python's standard library for parsing URLs and making HTTP requests.
python3 urlbox.pyAfter running the script, click the Usage tab in the dashboard. You should see a page like this:
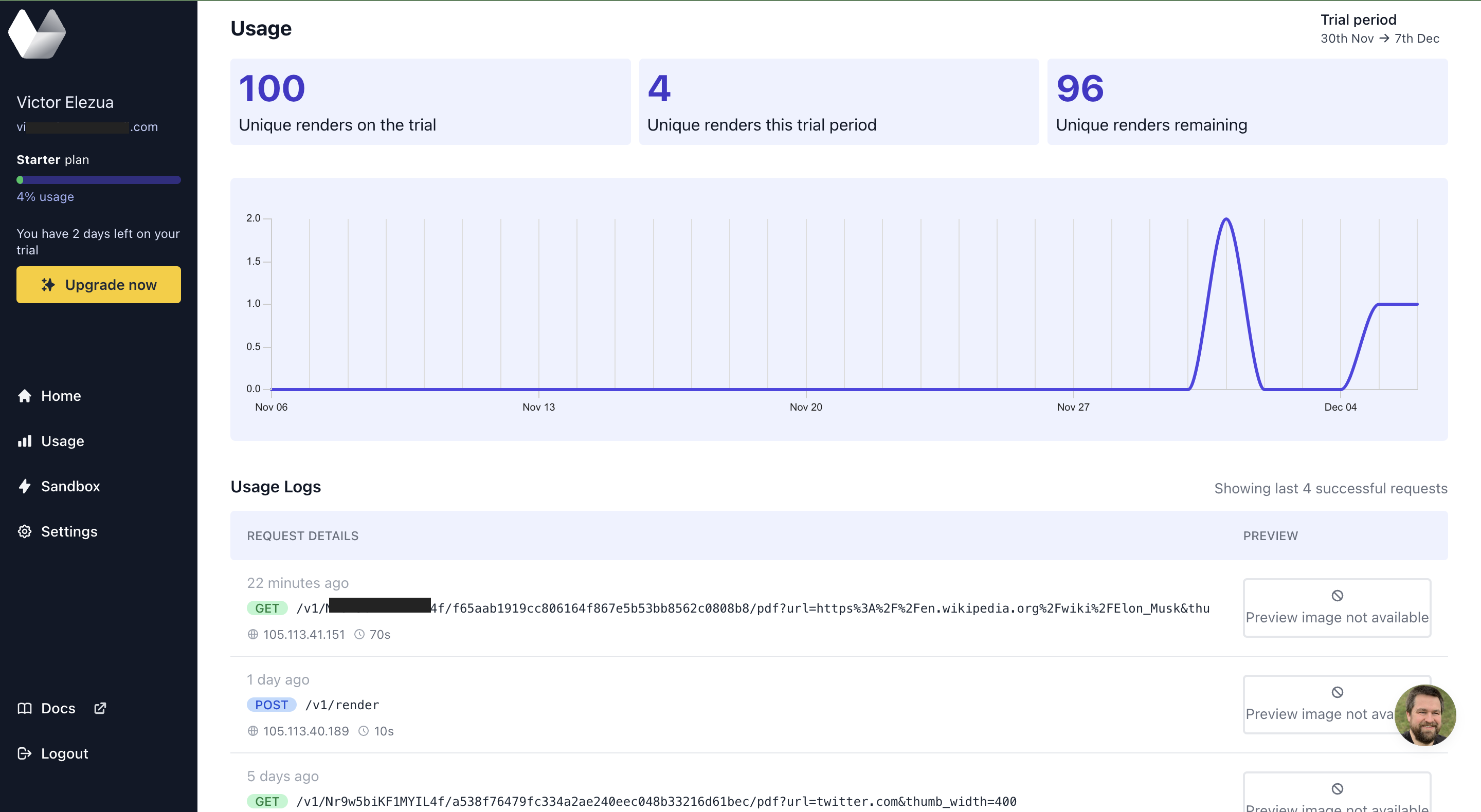
Under the Usage Logs section, click the preview of the first log; it should be the last converted PDF.

You can take a look at the converted PDF shown in the previous image here.
Options
Now that you’ve seen the basics of Urlbox, let’s take a quick look at some of the customizations you can explore. Buckle up—there’s a lot here, and we don’t get to everything!
Basic Options
The basic options that are available are:
width. Sets the browser's viewport width in pixels.height. Refers to the browser's viewport height used to render the HTML that is to be converted to a PDF.full_page. Tells the Urlbox API to cram all the HTML content into a single-page PDF.
*Blocking Options
block_ads. Stops ads from popular advertising networks from loading on the web page to be converted.block_urls. Stops requests from the specified URLs from loading.hide_cookie_banner. Automatically hides cookie banners from most websites.click_accept. Automatically clicks accept buttons in order to dismiss popups.hide_selector. Hides elements by passing a comma-delimited string of CSS element selectors.
Customize Options
You can use these options to customize the look of the web page before rendering a screenshot:
js. Injects and executes custom JavaScript on the web page before rendering.css. Injects custom CSS into the web page.dark_mode. Emulates dark mode on most websites by settingprefers-color-scheme: dark.reduced_motion. Sets the preference of the website's animation toprefers-reduced-motion: reduced.
Image Options
These options customize the output of PNG, JPEG, or WebP files:
retina. Takes a high-definition screenshot, equivalent to setting a device pixel ratio of 2.0. Note that the processing time will be longer than usual.thumb_height. Sets the height of the generated thumbnail in pixels it can be omitted for a full-sized screenshot.thumb_width. Sets the width of the generated thumbnail in pixels it can also be omitted for a full-sized screenshot.quality. Sets the image quality of the resulting screenshot for JPEG and WebP only.transparent. Renders the resulting screenshot with a transparent background, if the web page has no background color set.max_height. Useful for extremely lengthy websites. However, you might want to consider limiting the screenshot to a maximum height to prevent Urlbox from scrolling a long time just to generate an enormous screenshot.download. Makes the resulting Urlbox link downloadable you’ll be prompted to save the file with the filename passed with thedownloadquery parameter.
PDF Options
These are options relating to PDF generation:
pdf_page_size. Sets the PDF page size available options includeA0–A6,Legal,Letter,Ledger, andTabloid. Note that settingpdf_page_sizetakes precedence overpdf_page_widthandpdf_page_height.pdf_page_widthandpdf_page_height. Set the width and height of the PDF in pixels respectively.pdf_margin. Sets the margin of the PDF with three available options:none,default, andminimum.pdf_margin_top,pdf_margin_right,pdf_margin_bottom,pdf_margin_left. Set custom margins in pixels on the PDF.pdf_scale. Sets the scale factor on the website content on the PDF valid values are numbers between 0.1 and 2.pdf_orientation. Sets the orientation of the generated PDF to eitherportraitorlandscape.pdf_background. Sets background images to print in the generated PDF. By default, when generating a PDF, theprintCSS media query is used. To generate a PDF using thescreenCSS, set this option toscreen.
Cache Options
These options determine how Urlbox caches your screenshots or PDFs:
forceuniquettl
Request Options
These configure the browser before navigating to the URL:
proxyheaderaccept_langauthorizationuser_agentcookie
Wait Options
These give you the ability to control the length of the wait before carrying out certain actions:
delaytimeoutwait_untilwait_forwait_to_leavewait_timeout
Page Options
These modify the page state before taking a screenshot:
scroll_toclickclick_allhoverbg_colordisable_js
Full Page Options
These advanced options control how Urlbox takes full-page screenshots, when full_page=true. Available options are:
allow_infinitefull_widthskip_scrolldetect_full_heightmax_section_heightscroll_incrementscroll_delayturbo
Highlighting Options
These options highlight a given string on the page.
highlight. Selects the string to highlight before capturing the PDF.highlightfg. Specifies the text color of the highlighted word.highlightbg. Specifies the background color of the highlighted word.
Geolocation Options
These options emulate the Geolocation API:
latitudelongitudeaccuracy
Storage Options
These options relate to storing the screenshot in Amazon S3:
use_s3s3_paths3_buckets3_storagelass
Request Behavior Options
These dictate how Urlbox handles certain incidents:
fail_if_selector_missingfail_if_selector_presentfail_on_4xxfail_on_5xx
Conclusion
Obviously, there’s a lot you can do to customize HTML-to-PDF conversion, and there are a lot of tools on the market ready to help you with whatever task you have at hand.
No matter what tool you choose, keep in mind that generating PDFs is a job best done by a third-party service. The infrastructure required to generate PDFs at scale can quickly become an undesirable maintenance burden for an engineering team. Urlbox in particular has a robust and secure API to help you convert, customize, and manage HTML-to-PDF conversions securely at scale so you’re not distracted from your core product work.